
한 달간 준비했던 한능검 시험을 끝내고,
수요일 수업을 토요일에 와서 정리해보려 합니다 : )
수요일 수업은 한 챕터가 끝나고 중간에 새로운 챕터로 넘어가서
2개로 나누어 포스팅해보려 합니다!
여유로울 때 정리하니 머리에 쏙쏙 넣어야겠네요!!!
오늘도 파이팅!!!
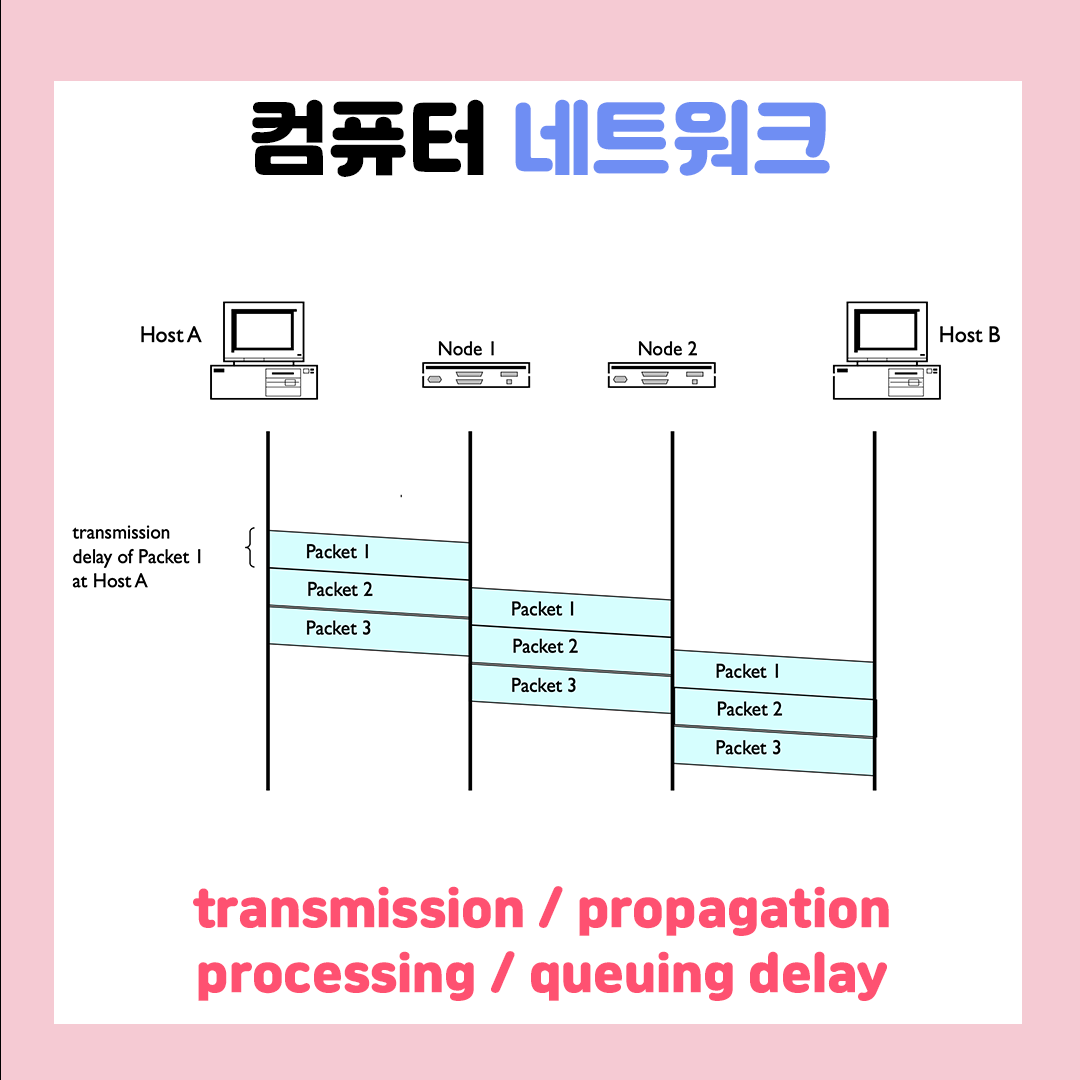
1. 네트워크에서 발생하는 4가지 지연을 알아봅시다. (packet switching)

라우터는 store and forward 방식으로 동작합니다. 패킷이 라우터에 도착하면 잠시 저장을 하고, 패킷을 어느 링크로 전달할지 결정하게 됩니다. 결정이 되면 해당 링크로 forwading 하게 됩니다.
전체 패킷이 라우터에 도착합니다. 그 후에 다음 링크로 전달됩니다. 그 사이에 발생하는 시간은 buffering(버퍼링)이 된다 라고 할 수 있습니다.
1-1. 데이터 처리에 걸리는 시간(=transmission)을 계산하는 방법
만약 L이 7.5 bit/packet(1패킷에 7.5 bit)이고, R이 1.5b/s(1초에 1.5bit 전송)일 경우(단, 버퍼링 시간 0), 얼마의 시간이 걸릴까요?
7.5 bit / 1.5 b/s = 5sec (1hop) 입니다. indirect에 경우 보통 2개 이상이니 hop을 잘 보시고 계산해야 합니다.
이 때 hop은 링크 수라고 생각하시면 됩니다.
즉, 위의 그림에서는 총 10초의 transmission delay가 발생합니다.

*정리하자면, hostA에서 hostB로 패킷 1개를 링크에다가 주입하는 시간을 transmission delay라고 합니다.
+plus
음료수를 먹는다고 생각했을 때 정말 가느다란 빨대와 정말 굵은 빨대로 음료소를 먹을 때 어느 때 음료수를 더 빨리 먹을 수 있을까요?
두 빨대의 길이가 동일하다면, 굵은 빨대로 먹는 것이 더 빠르게 먹을 수 있습니다.
이렇게 생각하는 것의 원리가 바로 transmission delay입니다.
여기서 굵은 빨대는 링크가 전달할 수 있는 데이터를 보낼 수 있는 속도인 bandwidth가 크다는 것을 의미합니다.
즉, 가느다란 빨대에 데이터를 보내는 것보다 굵은 빨대에 데이터를 보내는 것이 처리가 더욱 빨라지기 때문에 transmission delay가 감소합니다.
즉, transmission delay는 데이터 bandwidth(대역폭)과 데이터 사이즈에 영향을 받습니다.
전달할 데이터의 크기가 작으면 작을수록 빨리 다음 host에 전달할 수 있고, 링크 속도 (bandwidth)이 빠르면 빠를수록 신속한 데이터 처리가 가능합니다.
1-2. propagation delay?
만약 link의 전송속도가 무한대라면, 즉 빨대가 어어어엄청~~ 크면 전송 속도가 0초에 수렴할까요?
실제 데이터는 link에서 전파형태로 이동합니다. 이 때 link capacity가 무한대 (=transmission delay=0)여도 목적지까지 데이터가 전송되는데 걸리는 시간이 발생한다.
서울에서 미국까지 데이터를 보낼 때 아무리 link capacity가 무한대라고 하더라고 0초만에 데이터를 보낼 수는 없습니다. 그 이유는 출발지와 목적지 사이에 거리와 전파가 전달되는 속도 때문입니다. 일반적으로 전파가 전달되는 속도는 거의 빛의 속도라고 생각하시면 됩니다. 빛의 속도도 0초는 아니죠 ^^ 때문에 출발지와 목적지 사이에 거리가 멀수록 시간이 더 드는 것이고, 전파가 전달되는 속도에도 영향을 받습니다.
node와 node 사이의 거리가 짧으면 짧을수록 전달 시간은 0에 가까운데, 멀면 propagation delay를 무시할 수 없습니다.
+ plus
transmission delay : 데이터 사이즈와 링크의 전송 속도
vs
propagation : 노드 사이의 거리, 전파의 전송속도
한국은 땅덩어리가 작아서 propagation delay가 작지만, 미국은 커서 propagation delay를 무시하지 못합니다.
우리가 위성 통신을 썼을 때도 시간이 많이 걸렸던 이유가 propagation delay 때문입니다.
1-3. 데이터 전송할 때마다 생기는 간격은 무엇을 의미할까?
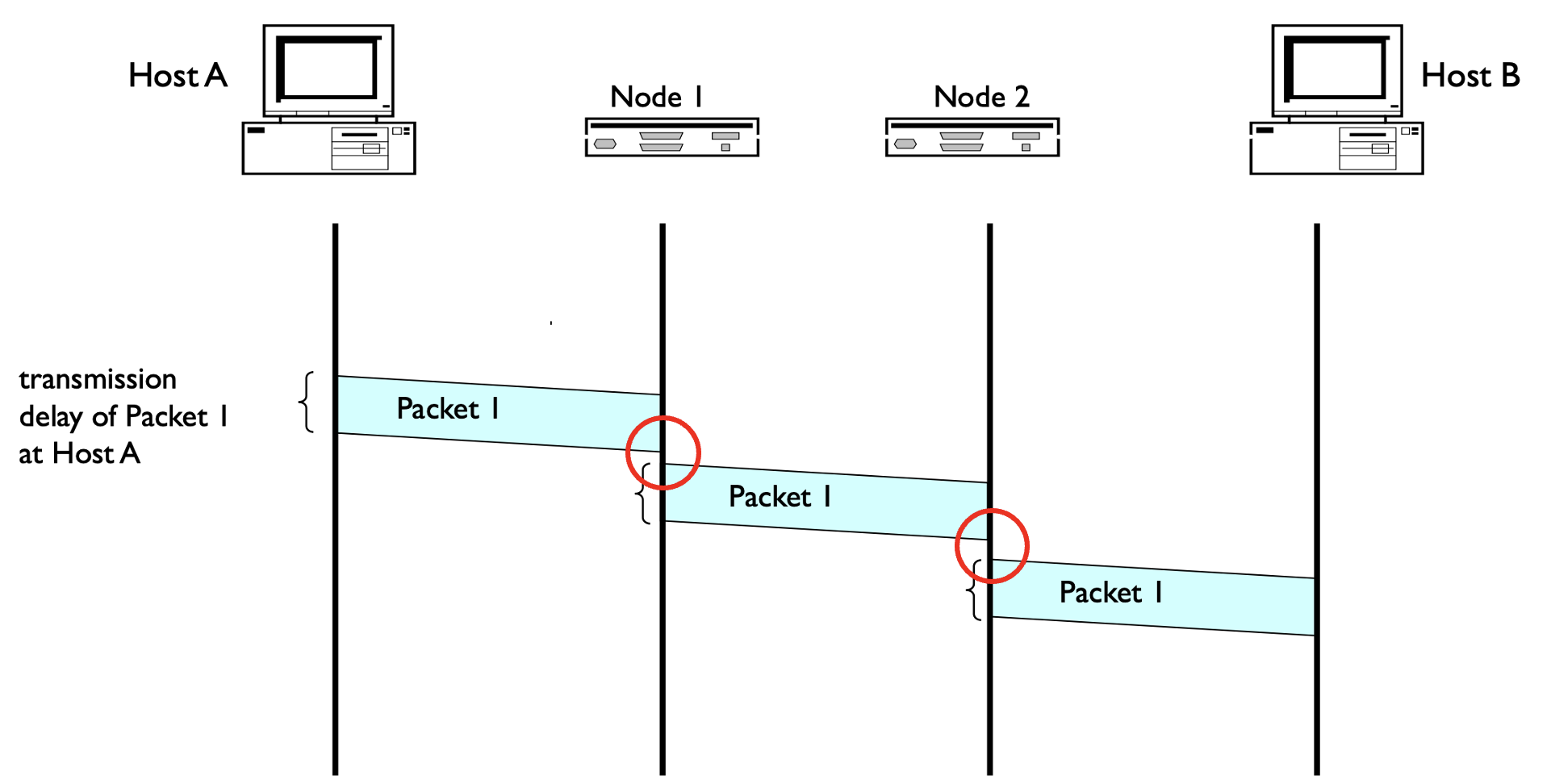
라우터에 머무는 버퍼링 시간입니다. 패킷을 다음 노드에 전달하고, 라우터에 임시저장되며 머무르고, 전달하고 머무르고의 반복이죠.
라우터는 패킷의 head에서 ip를 리드하고, 라우팅 알고리즘을 기반으로 생성된 포워딩 테이블을 보고서 어느 링크로 맵핑해야하는지 판단해야합니다. 이것을 매 패킷이 도착할 때마다 이루어져야하는 판단의 과정으로 시간이 소요됩니다.
즉, 라우터에 머물며 ip를 리드하고, 포워딩 테이블을 확인하는 일련의 버퍼링 시간을 processing delay라고 합니다.
그리고 라우터에서 이 패킷은 2번 패킷으로 가는 것이 좋겠다 판단을 내렸습니다. 그 후엔 바로 링크로 데이터가 들어갈까요?
큐에서 순서대로 나가야하기 때문에 queuing delay가 발생합니다.
일반적으로 processing delay는 아주 작고, queuing delay는 가변적입니다 0에서 수초까지 시간이 걸리기 때문이죠.
네트워크에 트래픽이 없고, 큐에 아무것도 쌓여있지 않다면, 큐잉 딜레이는 0입니다.
<4가지 지연 정리>
1) transmission delay : 링크에 데이터를 주입할 때 발생하는 지연 (대역폭, 데이터 사이즈 관련)
->대비책은 대역폭을 늘리거나 데이터 사이즈를 압축시킵니다.
2) propagation delay : 전파가 물리적인 거리를 따라 타고 들어갈 때 발생하는 지연 (노드 사이의 거리, 전파 속도 관련)
-> 대비책은 노드 사이의 거리를 줄이기 위해 서버를 전진 배치합니다. (=edge computing)
3) processing delay : 라우터에 도착해서 몇 번째 포트로 전달될지 판단되는 시간
4) queuing delay : 나보다 먼저 도착한 큐가 처리되는 것을 기다리는 시간
2. Packet switching : queuing, delay, loss
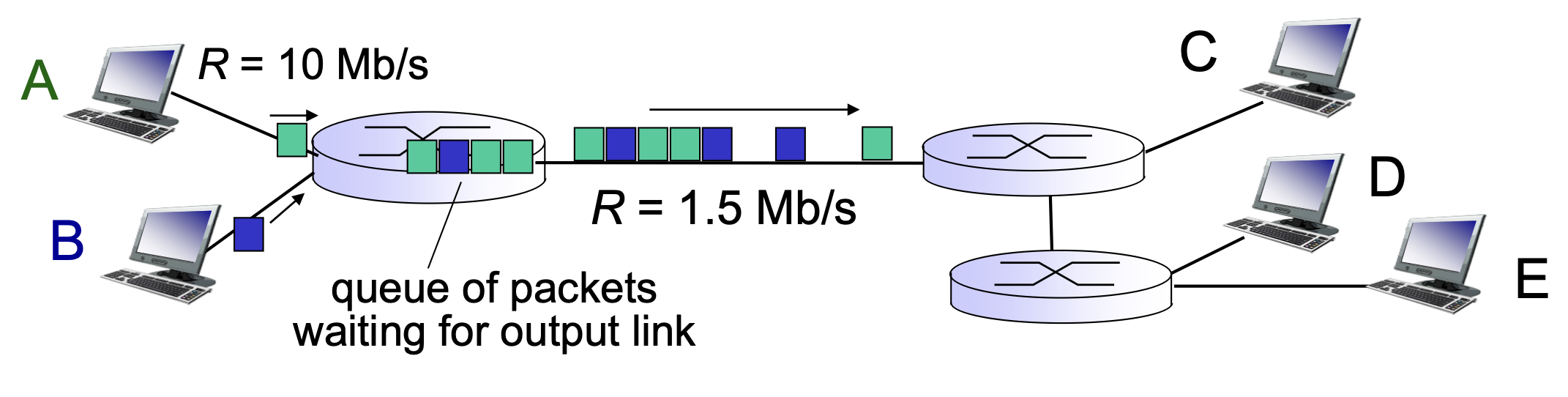
현재 그림은 input 링크 2개 output 링크 1개를 가진 라우터를 보여주고 있습니다.
라우터는 패킷의 헤더 (소스 IP, destination ID 등)를 보고, 패킷을 어느 경로로 forwarding 해야하는지 판단하고 그 링크로 패킷을 전달합니다.
1-1. bandwidth == link capacity
링크가 전달할 수 있는 데이터를 보낼 수 있는 속도가 있는데요.
그 속도를 bandwidth 또는 link capacity라고 합니다.
예시로 위의 그림에서 보면 라우터와 라우터를 이어주는 링크는 1.5 bandwidth를 가지고 있는 것을 확인할 수 있습니다.
1-2. output 링크보다 Input 링크로 들어오는 속도가 더 빠르다면?
라우터는 store and forward 방식입니다.
store 즉, 임시저장을 위해서 라우터는 메모리를 가지고 있습니다. forwarding을 하기 전까지 잠시 머무르는 장소이죠.
그리고 라우터에 데이터가 쌓이는 모습을 큐잉(queuing)이라고 합니다.
1-3. 라우터에 제한된 메모리 이상의 데이터가 들어온다면?
라우터에 메모리를 넘는 데이터가 들어온다면, overflow가 발생해서 데이터가 유실됩니다.
데이터가 유실되는 것을 다른말로 packet loss라고도 부릅니다.
패킷의 input link의 arrival rate(도착속도)가 output link의 trans rate(내보내는 속도)보다 빠르게 된다면, 라우터에 큐가 쌓이게 되고, 자연스럽게 큐잉 딜레이(queuing delay)가 발생하게 됩니다. 만일 큐가 점점 늘어나서 더 이상 저장할 공간이 없게 된다면, 결국에는 loss가 발생합니다.
3. Packet switching vs Circuit switching

헤더에는 목적지 주소 같은 정보들이 포함되어 있습니다.
3-1. 서킷스위칭에서 헤더란?
그러면 서킷스위칭에서는 헤더가 필요할까요?
정답은 아니요 입니다 : )
서킷스위칭 방식은 출발지에서 도착지까지 처음부터 회선을 만들고 시작합니다.
때문에 다른 회선으로 갈 필요도 없어서 라우팅 기능도 필요하지 않습니다.
3-2. 서킷스위칭을 다시 한 번 알아보자
서킷 스위칭은 회선을 잡는 데 시간이 오래걸리고,
리소스가 회선을 잡고있는 노드들에게 독점되기 때문에 비효율적으로 링크가 사용됩니다.
패킷단위로 데이터를 쪼개지 않고, 라우팅도 안해도 되기 때문에 overhead가 되지 않는다는 장점을 가지고 있습니다.
3-3. 패킷스위칭을 다시 한 번 알아보자
패킷을 자칫 잘못 관리하면, 즉, 데이터를 무분별하게 흘려보내면 데이터 손실과 congestion이 발생합니다.
즉, 큐잉 딜레이, 패킷 로스가 발생한다는 의미입니다.
이런 혼잡 문제는 인터넷이 느려지는 결과를 가져옵니다. (뒤에서 배우겠지만 이를 위해 나온 프로토콜로 TCP가 있습니다.)
하지만 서킷스위칭에서는 데이터 혼잡, 로스가 발생하지 않죠.
서킷스위칭은 안정적으로 데이터를 관리할 수 있는 반면, 패킷스위칭은 불안정합니다.
그럼에도 불구하고 패킷 스위칭을 사용하는 이유는 링크의 효율이 높기 때문이에요.
3-4. 링크 효율성에 대해 알아보자
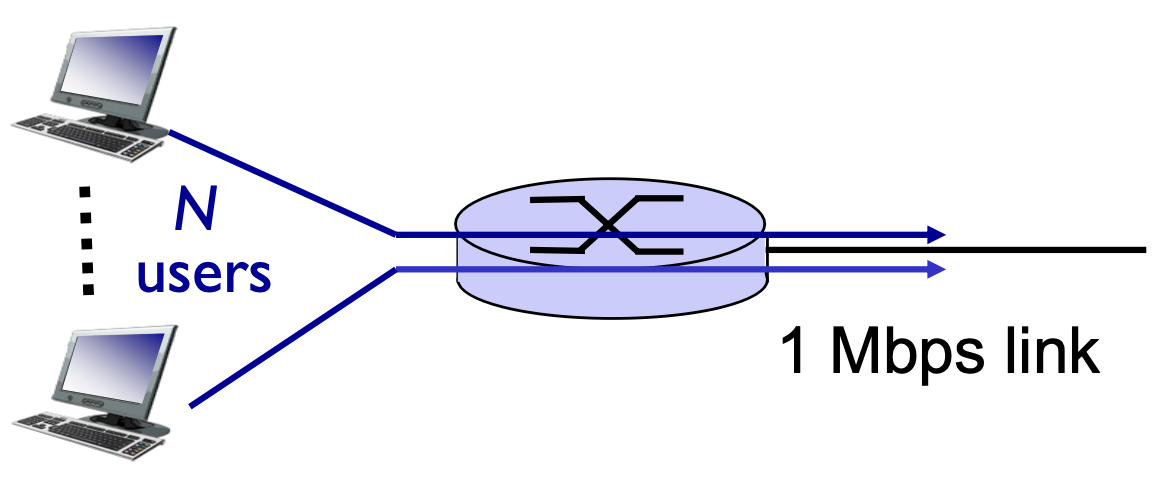
만약 링크는 1Mbps이고, 각각의 유저는 100Kbps의 트래픽을 발생시킨다고 가정해봅시다.
유저는 100% 중 10%만 데이터 발생시키고, 90%는 노는 트래픽 패턴을 가지고 있습니다.
카카오톡을 하루 종일 잡고 있지 않는 것처럼 말이죠.
만약 서킷스위칭 방식이라면, 몇 명의 유저를 동시에 수용할 수 있을까요?
링크가 처리할 수 있는 데이터 속도를 한 사람이 발생하는 트래픽으로 나누면 됩니다.
즉, 한 명의 유저는 100Kbps = 100x10^3 = 1초에 10만 트래픽을 발생시키고,
링크는 1Mbps = 1x10^6=1초에 100만 트래픽을 처리할 수 있습니다.
서킷의 경우 100만트래픽/10만트래픽 = 10명을 수용할 수 있습니다.
패킷의 경우 정확하게 계산할 수 있는 방법은 없지만 결과적으로 저 상태에선 35명을 동시에 수용할 수 있다고 합니다.
이 예제만 보더라도 링크 사용률은 패킷 스위칭 방식이 3.5배가 더 좋습니다.
+plus
망중립성에 대하여
: 미국에서 넷플릭스가 발생시키는 트래픽이 30%가 넘어간다고 합니다.
넷플릭스 때문에 인터넷이 느려진다고 하니 넷플릭스 측에서는 돈을 더 내고, 넷플릭스 유저들 인터넷 끊기지 않게 요청했다고 합니다.
통신사 측에서는 반기지만, 망중립성에 위배되는 상황이기 때문에 미국에서는 논란이 많았습니다.
네트워크는 돈이 많든 적든 데이터를 공평하게 쓸 수 있는 공용망입니다.
돈을 많이 내는 사람이 인터넷을 점유할 수 있는 길을 열어주는 것은 망중립성에 맞지 않다라는 의견도 있습니다.
다음 4-2 포스팅은 내일 차분히 해보며,
다음주 디스커션을 준비해야겠네요 = _ =
'CS > 컴퓨터 네트워크' 카테고리의 다른 글
| 컴퓨터 네트워크 5일차 : Throughput, Layering, ISP, Network Security (0) | 2021.09.14 |
|---|---|
| 컴퓨터 네트워크 4-2일차 : 네트워크 delay / traceroute / Packet loss / Throughput (0) | 2021.09.13 |
| 컴퓨터 네트워크 3일차 : 네트워크 계층, circuit vs packet 스위칭 (1) | 2021.09.07 |
| 컴퓨터 네트워크 2일차 : 라우터, 네트워크, 프로토콜 전반적인 이해 (0) | 2021.09.01 |
| 컴퓨터 네트워크 1일차 : 컴퓨터로 소통하기 위해 필요한 것들 (0) | 2021.08.31 |