

컴퓨터 네트워크 7일차 : HTTP 프로토콜, 쿠키, 웹캐시, 이메일, DNS
컴퓨터 네트워크 6일차 : 어플리케이션 구조, 소켓, 어플리케이션 레이어 프로토콜, HTTP connection 컴퓨터 네트워크 5일차 : Throughput, Layering, ISP, Network Security 0. Review Discussion 0-1) 서킷스위..
tksgk2598.tistory.com
7일차에 이은 8일차 공부 시작합니다~!
저번 시간 DNS에 이어 적어볼게요~
1. DNS 서버
1) 루트 네임 서버

루트 네임 서버는 전세계 13곳에 존재합니다.
2) 탑 레벨 도메인 (TLD) 서버
com, org, net, edu와 같은 탑 레벨 도메인을 찾아주는 서버 입니다.
3) Authoritative DNS 서버
보통 기관에서 관리하는 서버 입니다. 예를 들어 아마존과 같은 회사와 조직에서 직접 관리 합니다.
4) Local DNS 서버
각각의 ISP가 가지고 있습니다. 또한 default name server라고 부릅니다.
커맨트 창에서 ipconfig/all이라 입력하면, 아래와 같은 화면이 뜨게 됩니다.
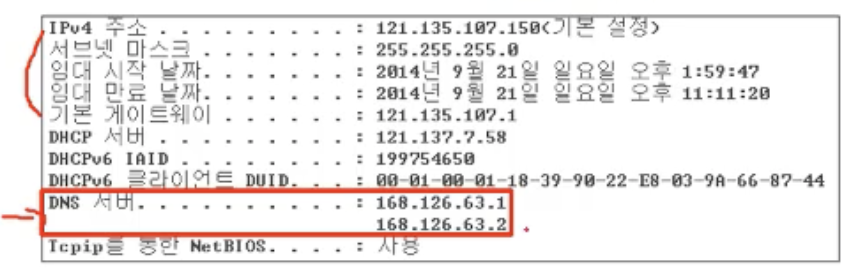
ip주소 뿐 아니라 DNS 서버의 주소가 나오게 됩니다. 이 주소가 바로 로컬 DNS 서버 주소입니다.
우리가 DNS 쿼리를 먼저 보내게 되면, 항상 내가 가입한 ISP의 Local DNS 서버로 쿼리가 먼저 보내지게 됩니다. 자신에게서 가장 가까운 DNS 서버라고 생각하시면 됩니다.
이 DNS는 가장 최근에 검색했던 host name과 ip주소 간의 맵핑을 캐싱을해서 가지고 있습니다. 물론 IP주소와 호스트 네임 간의 관계는 변할 수 있습니다. 오래된 정보가 된다는 것이죠 (=out of date)
Local DNS는 프록시 역할을 합니다. 자기의 로컬 캐시에 맵핑이 저장되어 있으면 루트 DNS에 물어볼 필요 없이 바로 ip주소를 제공합니다. 만약 가지고 있지 않다면, 쿼리를 계층에 따라서 전달하게 됩니다.
1-1. DNS name resolution example
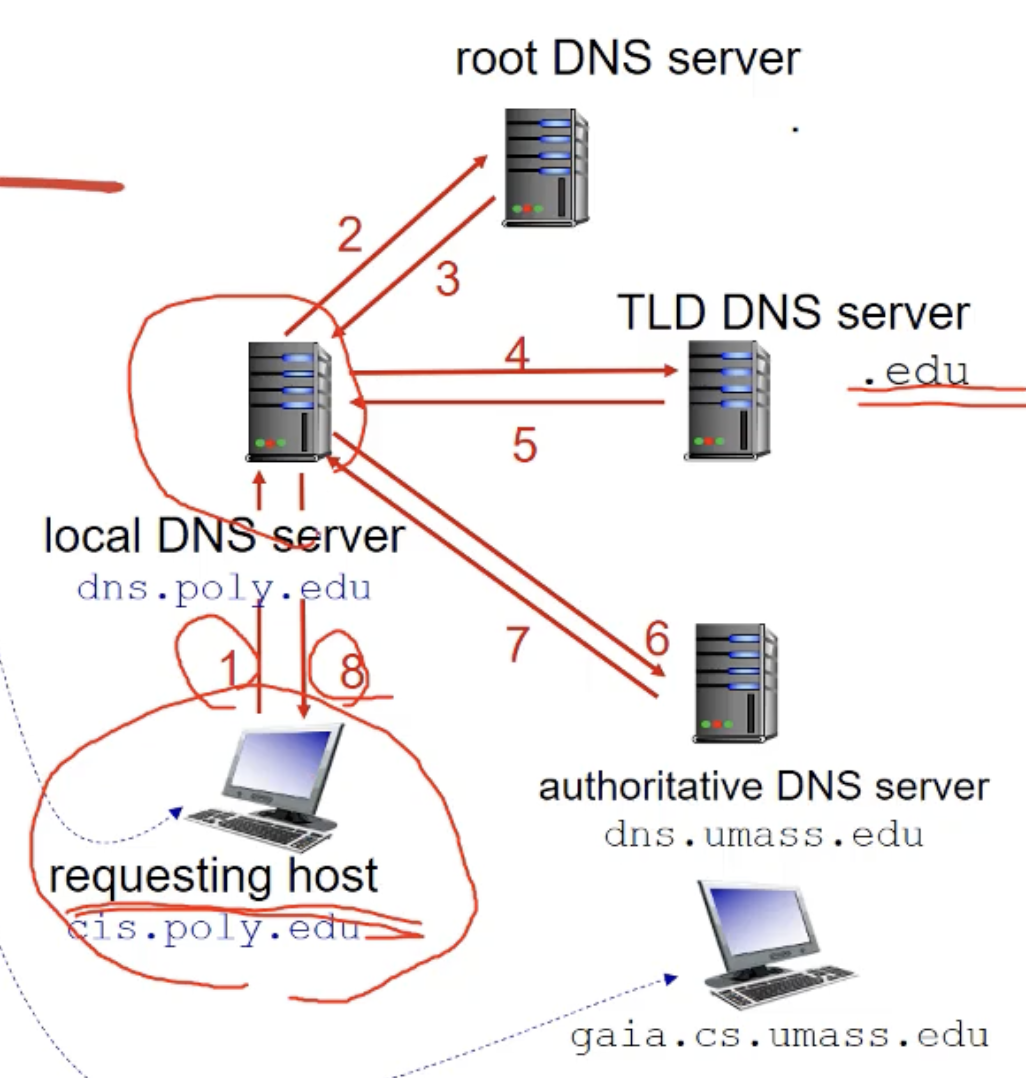
cis.poly.edu의 호스트가 gaia.cs.umass.edu에 접속하고 싶어합니다. 그렇다면 DNS를 통해서 ip주소를 얻어와야 합니다. 얻어오는 방법에는 몇가지 방법이 있는데요.
방법 1 - iterated query
호스트는 자신의 로컬 DNS 서버에게 물어봅니다. 그럼 로컬 DNS 서버는 gaia.cs.umass.edu 호스트의 ip주소를 가지고 있으면 바로 알려줄 겁니다.(캐싱된 것이 있다면 알려준다) (1)
하지만, 가지고 있지 않다면 로컬 DNS 서버는 루트 DNS 서버와 컨택하게 됩니다. (2)
그 후 루트 DNS 서버는 TLS DNS 서버의 주소를 로컬 DNS 서버에게 알려줍니다. (3)
그럼, 로컬 DNS 서버는 TLD DNS 서버 중에서 .edu를 관리하는 서버와 컨택하게 됩니다. (4)
TLD DNS 서버는 gaia.cs.umass.edu와 관련된 authoritative DNS 주소를 로컬 DNS에게 알려줍니다.(5)
그럼, 로컬 DNS 서버는 authoritative DNS 서버와 컨택하게 됩니다. (6)
authoritative DNS 서버는 gaia.cs.umass.edu의 ip주소를 로컬 DNS에게 알려줍니다. (7)
마지막으로 로컬 DNA 서버는 requesting host에게 ip주소를 알려주게 됩니다. (8)
방법 2 - recursive query
호스트는 자신의 로컬 DNS 서버에게 물어봅니다. 그럼 로컬 DNS 서버는 gaia.cs.umass.edu 호스트의 ip주소를 가지고 있으면 바로 알려줄 겁니다.(캐싱된 것이 있다면 알려준다) (1)
하지만, 가지고 있지 않다면 로컬 DNS 서버는 루트 DNS 서버와 컨택하게 됩니다. (2)
지금부턴 방법1과 좀 다릅니다.
루트 DNS 서버는 로컬 DNS 서버가 아닌 자신이 직접 TLD DNS 서버와 컨택합니다. (3)
그러면 TLD DNS 서버는 authoritative DNS 서버와 컨택하게 됩니다. (4)
authoritative DNS 서버는 ip주소를 TLD DNS 서버에게 알려줍니다.(5)
TLD DNS 서버는 루트 DNS 서버에게 ip주소를 알려줍니다. (6)
루트 DNS 서버는 ip주소를 로컬 DNS 서버에게 알려줍니다 (7)
로컬 DNS 서버는 최종 host에게 알려주게 됩니다. (8)
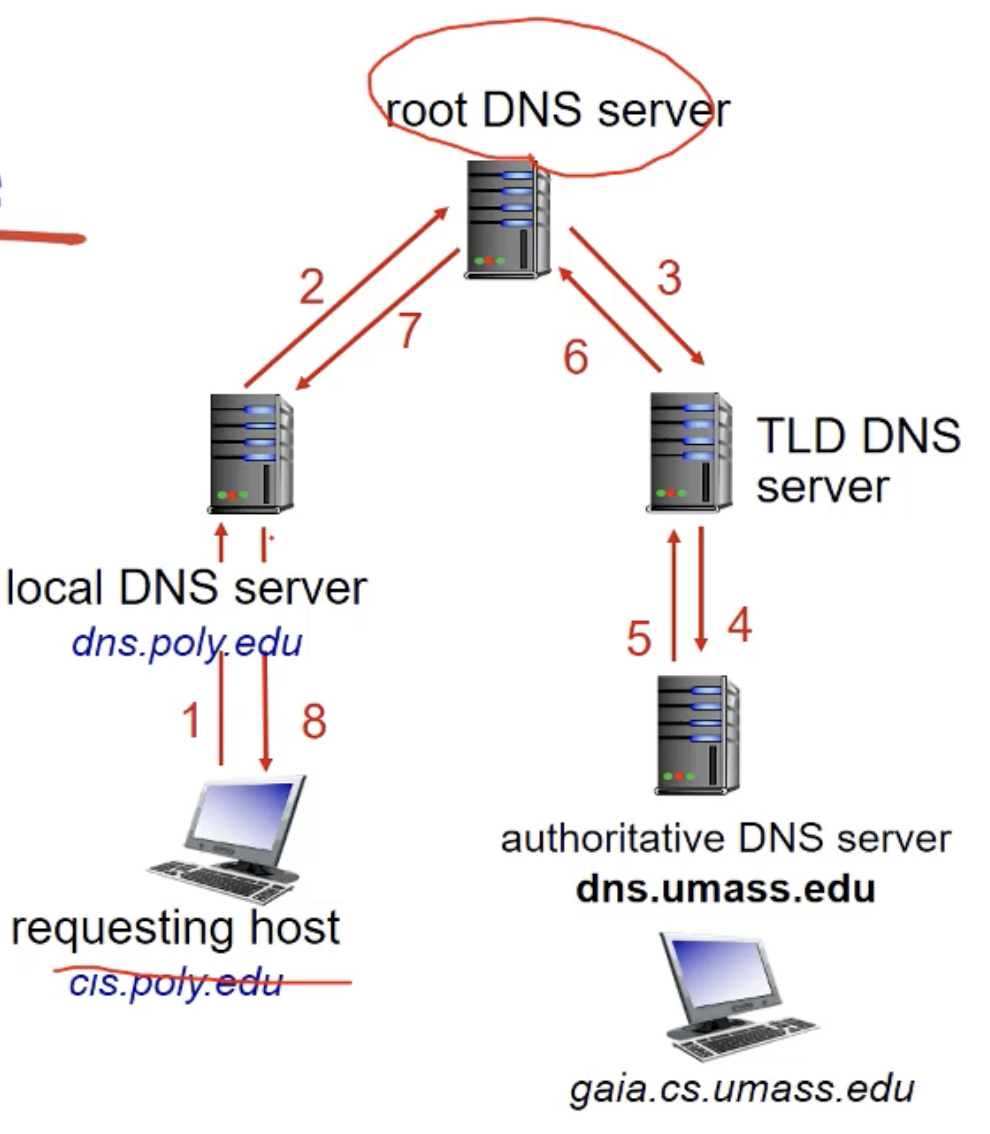
이 방식은 상위 레벨의 DNS 서버에 (루트 DNS 서버)에 heavy load가 발생할 수 있다는 단점이 있습니다.
1-2. 캐싱의 문제점
사람들이 www.naver.com을 많이 입력하면, 네이버의 ip주소를 캐싱합니다. 하지만 계속 저장해두면, out-of-date 즉, 싱크가 안맞는 경우가 종종 생깁니다. 이를 방지하기 위해서 캐시도 time out 값을 운영하게 됩니다. 일정시간 지나면 날려버린다는 의미입니다.
1-3. load distribution
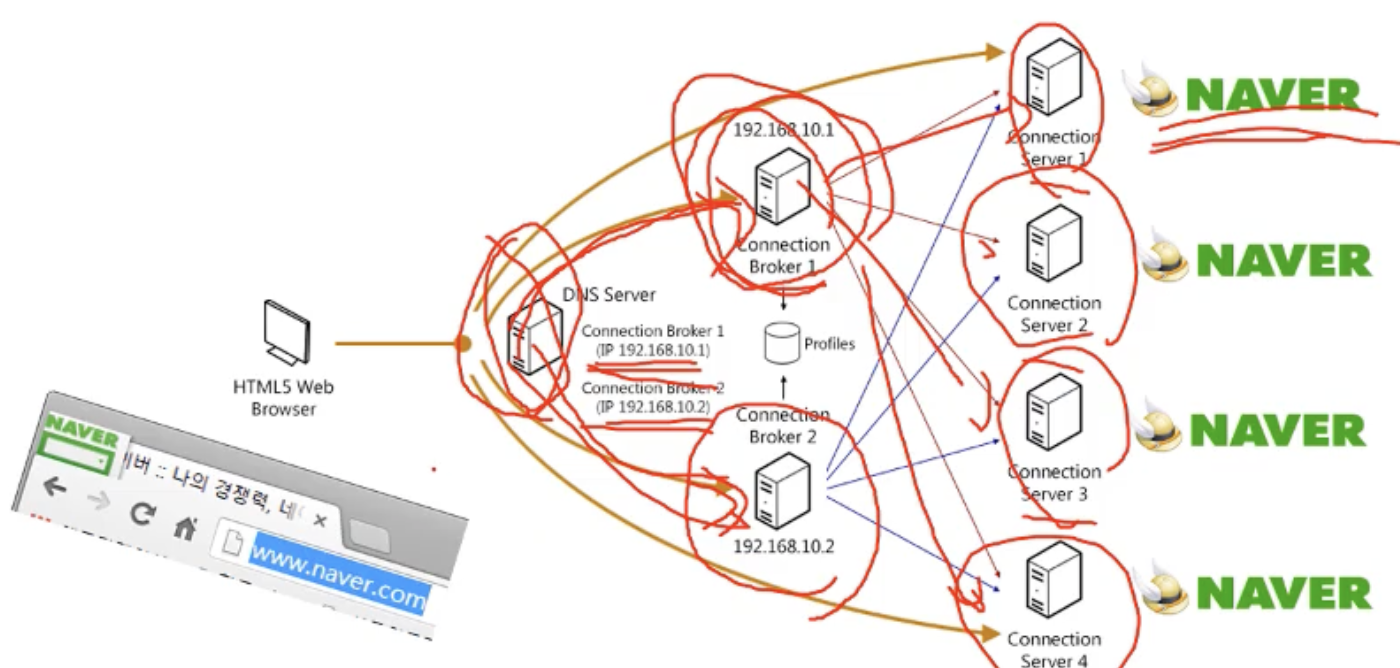
DNS는 ip주소 맵핑 말고도 load distribution 역할을 합니다. 네이버는 여러 대의 서버를 가지고 있습니다. 왜냐하면 노드를 분산시키기 위함입니다.
만약 내가 네이버 주소를 검색창에 입력하면, DNS 서버가 ip 주소들 중 하나의 주소로 안내를 해줍니다. 만약 커넥션 브로커 1의 ip주소로 안내 받았다면, 해당 브로커가 관리하고 있는 n개의 노드를 파악해 노드가 적은 방향으로 또 안내합니다. 특정 서버에 과부하가 걸리지 않도록 말이죠! (load balancing 역할)
2. P2P 어플리케이션
2-1. P2P 아키텍쳐
큰 특징이 있었죠. no always-on server 즉, 항상 켜져있는 서버가 존재하지 않습니다.
임의의 end system이 직접 커뮤니케이션하는 구조입니다. 이 때 P2P에서는 임의의 엔드 시스템을 peer라고 부른다고 했습니다. peer들은 간헐적으로 서비스를 원할 때 연결이 됩니다. 동적인 ip주소를 할당 받으며, 참여하게 됩니다.
대표적으로 file distribution(Bit Torrent) / Streaming(KanKan) / VoIP(Skype) 가 있습니다.
2-2. file distribution : client server vs P2P
하나의 서버에서 N peer들에게 사이즈 F의 파일을 distribution하는데 시간이 얼마나 걸릴까요?
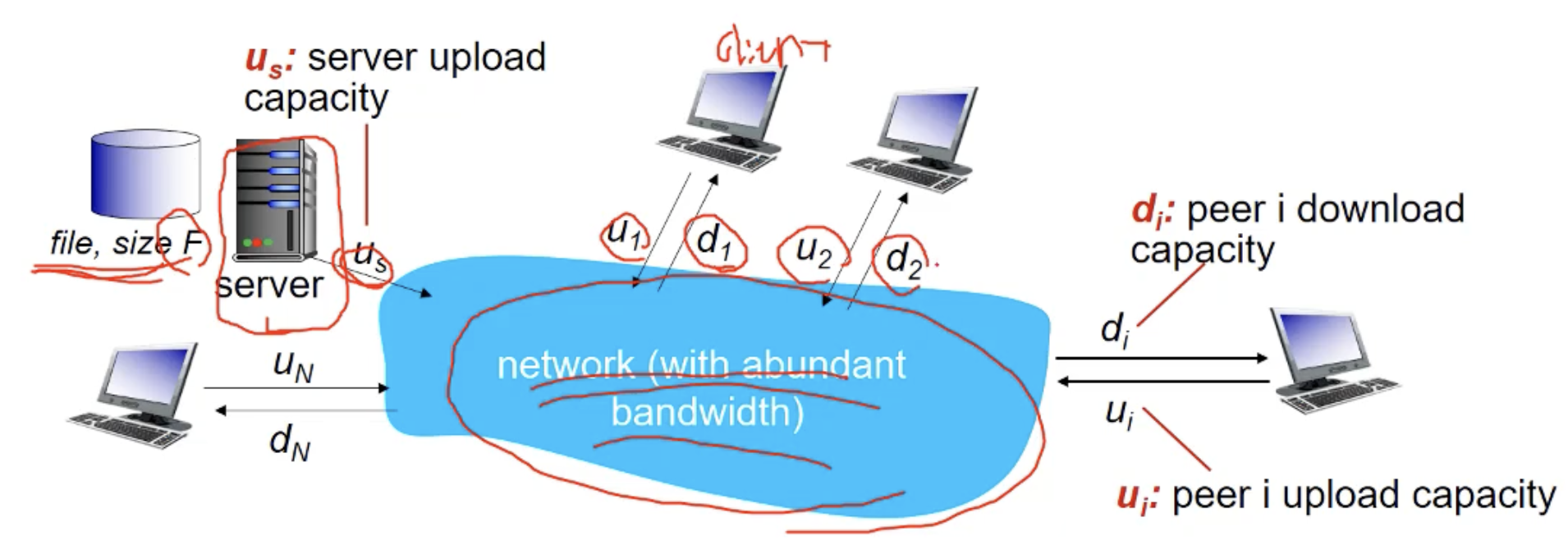
1) client server 구조에서 파일 배포 시간
파일 F의 N개의 copy를 전부 네트워크를 통해서 전송해야합니다. N개의 카피는 Us(보틀넥 링크)를 거쳐서 네트워크로 전달이되어야 각각의 노드들이 카피를 받을 수 있습니다.
즉 하나의 카피를 보내는 시간은 F/Us로 하나의 파일 사이즈를 보틀넥 링크로 나눈 것이 됩니다. N개의 카피는 N개를 곱하면 됩니다. 즉, N*F/Us입니다.
추가로 네트워크를 통해 복사된 파일을 받는 노드들 중 가장 느린애가 다운을 완료한다면, 모든 노드가 다운을 완료했다고 볼 수 있습니다. 이것을 dmin(다운로드시간) = min client download rate라고 표현할 수 있습니다.
즉, 가장 느린 노드가 파일 다운을 완료하는 데 걸리는 시간은 F/dmin입니다.
결과적으로 F 사이즈의 파일 N개를 모든 클라이언트가 받는데 걸리는 시간을 이렇게 표현할 수 있습니다.
=> D(c-s) >= max{NF/Us, F/dmin}
파일 배포와 동시에 노드들이 파일을 다운받으므로 이 중 가장 시간이 많이 걸리는 애가 distrubution에 걸리는 시간입니다. (=D(c-s))
2) P2P 구조에서 파일 배포 시간
peer들끼리 파일을 공유합니다. 때문에 오리지널 서버가 파일을 배포한다고 가정해봅시다. 클라이언트 서버에서는 서버 역할이 1개였기 때문에 N개를 배포했어야했습니다. 하지만, P2P구조에선 peer가 클라이언트&서버 역할을 대신 해주기 때문에 1개의 카피만 흘려보내도 됩니다. 때문에 F/Us만 걸리는 거죠.
또한 min client download time은 F/d(min)입니다.
어쳐피 N개의 노드들에게 파일이 배포되어야하므로 NFbit가 들어갑니다.
모든 클라이언트는 파일을 받음과 동시에 배포하는 주체가 됩니다. 때문에 max upload rate = Us+(모든 노드의 업링크 속도 합)Ui가 되는 것 입니다.
결과적으로 F 사이즈의 파일 N개를 모든 클라이언트가 받는데 걸리는 시간을 이렇게 표현할 수 있습니다.
=> D(P2P) >= max{F/Us, F/dmin, NF/(Us+모든 노드의 업링크 속도의 합)}
파일 배포와 동시에 노드들이 파일을 다운받고 배포함으로 이 중 가장 시간이 많이 걸리는 애가 distrubution에 걸리는 시간입니다.
여기서, NF/(Us+모든 노드의 업링크 속도의 합)은 N(클라이언트 수)에 따라서 전체 배포해야할 파일의 수가 증가합니다. 또한 클라이언트의 업링크 capacity가 증가하게 됩니다 (=모든 노드의 업링크 속도의 합)
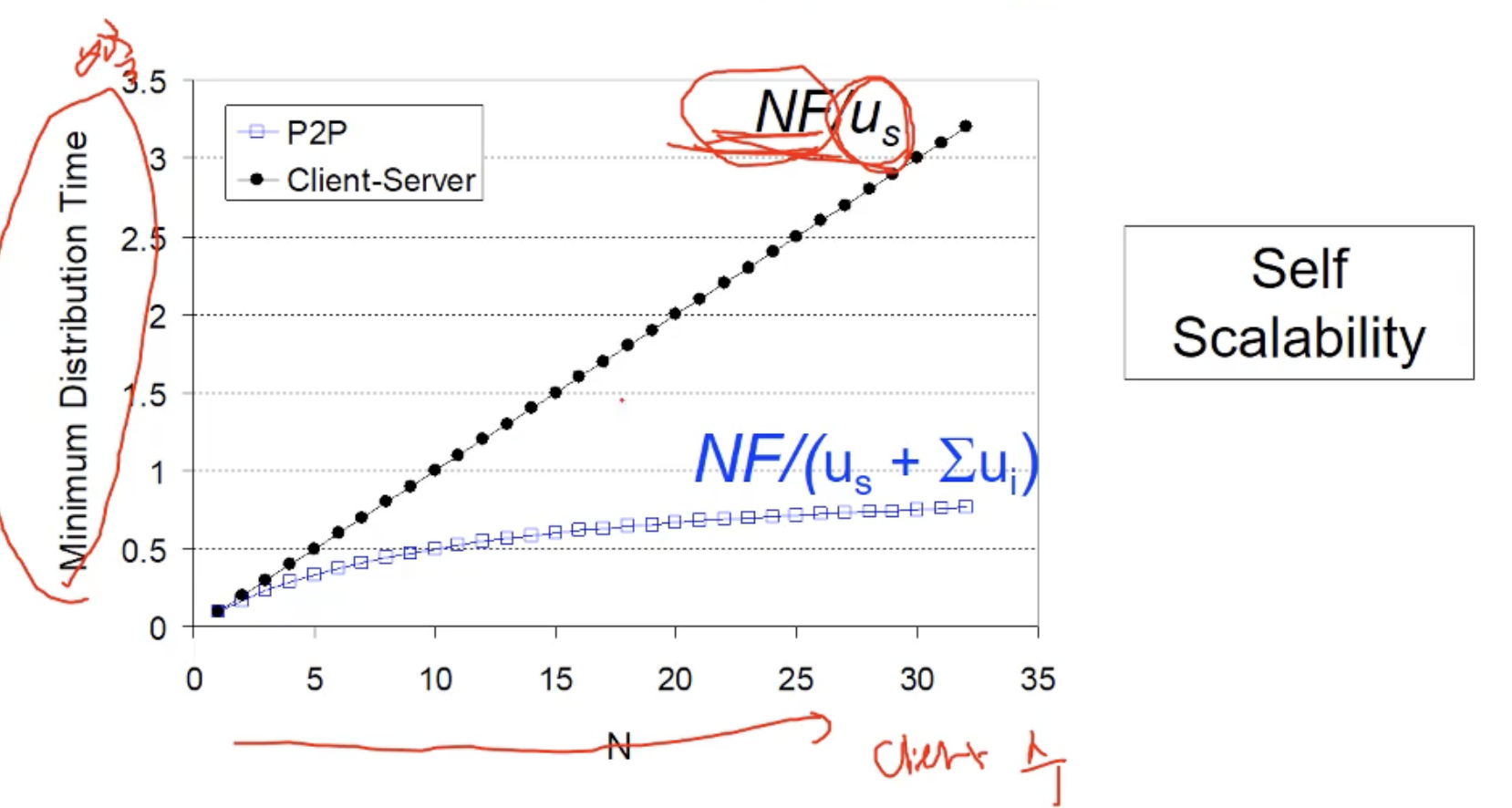
분자와 분모가 같이 증가하며 디맨드와 서플라이가 같이 증가하며 self scalability 갖게 되는 것입니다. 클라이언트-서버 구조와는 다른 양상을 알 수 있습니다.
이런 P2P 양상의 대표적으로 Bit Torrent가 있습니다.
2-3. file distribution : P2P : Bit Torrent (chunk)

이런식으로 잘게 chunk단위로 쪼개어진 256kb의 파일이 있습니다.
peer들은 이런 청크를 주고 받으면서 원하는 파일을 받게 됩니다. 그러다가 청크를 모두 받아오게 되면 원하는 파일을 구성할 수 있게 되는 것 입니다.

tracker : 비트 토렌트에 참여하는 peer들을 추적하고 관리합니다.
torrent : 청크들을 서로 공유하는 peer들의 그룹을 말합니다.
이 상황에서 앨리스가 비트 토렌트를 켜서 '라디오 스타'를 받고 싶다고 가정해봅시다.
트래커로부터 peer들 리스트를 얻게됩니다.
peer들로부터 내가 받고자 하는 파일에 청크들을 받게되고, 어느정도 청크가 쌓이게 되면 서버역할도 수행하게 됩니다. 이 때 청크를 받는 peer들은 매번 바뀝니다. 나랑 연결이 빠른 peer에게 받는 것이 좋기 때문입니다. 이렇게 peer들이 들어왔다 나갔다 하는 것을 churn이라고 합니다.
모든 청크를 모아 파일을 만들었으면 토렌토에서 빠져나갈 수 있습니다. 또는 토렌토에 남아서 배포하는 역할을 할 수 있습니다.
한편으론 저작권 문제 때문에 비트 토렌토를 안쓰기도 합니다.
2-4. P2P : Bit Torrent : chunk를 전략적으로 수집하는 법
청크를 요청할 때 특정 시간에 여러 peer들이 있지만, 갖고 있는 청크는 다 다릅니다. 주기적으로 앨리스는 peer들에게 갖고 있는 청크가 무엇인지 물어보게 됩니다. 여기서 peer들에게 주기적으로 물어보는 이유는 peer들도 실시간으로 가지고 있는 청크가 변화하기 때문입니다.
청크를 신속하게 모으기 위해 재밌는 알고리즘을 탑재하기도 합니다. peer들로부터 내가 갖고 있지 않은 청크들을 요청할 때 요청하는 순서를 peer들이 많이 갖고 있지 않는 청크들부터 우선적으로 요청하는 알고리즘입니다. 왜냐하면, peer들은 언제 떠날지 모르기 때문에 미리 희귀한 청크부터 받아놓아야 합니다.
2-5. P2P : Bit Torrent : chunk를 전략적으로 보내는 법
청크를 보내는 것도 전략적으로 보내야지 청크라는 시스템을 효율적으로 사용할 수 있습니다.
나에게 청크를 가장 빨리 보내준 peer에게 자신도 청크를 빨리 보내주게 됩니다. 왜냐하면 나에게 가장 빨리 보내준 peer와는 네트워크 상태가 잘맞기 때문입니다. 때문에 자신도 그런 대상들에게 빨리 배포하게 되면, 주어진 시간 안에 효과적으로 신속하게 청크 배포가 가능한 것입니다.
하지만 네트워크는 좋아졌다->나빠졌다 하는 가변의 성질을 가지고 있습니다. 때문에 10초마다 통신속도를 계속 평가를해서 top4를 재선정하게 됩니다.
한편으로 이런 알고리즘은 나와 먼 거리에 있지만 통신속도가 빠른 Peer들을 놓치게 될 수 있습니다. 이런 이유로 30초마다 랜덤하게 하나의 peer를 선택해서 교역을 합니다. 이것을 optimistically unchoked라고 합니다. 점차 이런 peer들과 교역하다보면 top4에 들어와 계속 교역하는 경우도 있습니다.(=unchocked) 교역하지 않은 peer들과는 데이터를 보내지 못합니다. (=chocked)

청크를 모두 모으게 되면 바로 떠나는 "FREE RIDER"가 존재하기도 합니다. 이런 문제점을 해결하기 위해 많은 연구를 했다고 합니다.
실제로 다운링크 유저는 많은데, 업링크 유저는 별로 없습니다. 서로 밸런스를 맞춰야 효과적으로 운영이 가능한데 말이죠...
3. 멀티비디오
넷플릭스는 전체 네트워크 트래픽의 37%를, 유튜브는 16%를 차지하고 있습니다. 이렇듯 데이터 볼륨도 크고 유저수도 빠르게 증가하고 있는데, 빠르게 증가하는 트래픽과 고객을 감당하기 위해서 scalability를 고려 안할 수 없습니다.
또한 유저들이 모두 다른 환경에 처해있습니다. 모바일/이더넷 (PC)로 보는 유저들과 같이 통신속도(bandwidth)가 모두 다릅니다. 이런 상황을 이기종성(heterogeneity)라고 합니다. 우리가 어떻게 안정적인 비디오 스트리밍을 제공할 수 있을 것이냐라는 문제점이 있습니다.
이런 점을 해결하고자 distributed / application-level infrastructure이 등장했습니다.
3-1. 멀티미디어 비디오 압축
비디오 영상이 어떤식으로 압축이되는지 알 필요가 있습니다. 비디오는 이미지의 시퀀스 입니다. 네트워크 상에는 굉장히 많은 이미지가 전송되는 격입니다. 이런 이미지들을 frame이라고 부릅니다. frame은 픽셀로 이루어져 있고, 픽셀에는 색깔을 나타내기 위한 값이 들어있습니다.
이런 비디오를 어떻게하면 더욱 압축해서 보낼 수 있을까를 생각해보아야 합니다.
1) 이미지 내에서 압축하는 방법 (=spatial coding)
이미지 내에 비슷한 색깔들이 모여있습니다. 같은 색을 N개 보내는 것은 정말 비효율적입니다. 때문에 색깔 값과 그 색깔 값이 몇 번 반복되는지 보내는 것이 데이터 양을 줄일 수 있는 방법입니다.

2) 이미지 차이로 압축하는 방법 (=temporal coding)
연속적인 프레임 안에는 이미지가 비슷합니다. 때문에 거의 똑같은 이미지를 2번 전달할 필요가 있느냐 하는 것 입니다. 프레임 간의 차이만 전달해줘서 그 다음 프레임을 예측해서 복원하는 방식을 말합니다.

3-2. 멀티미디어 비디오 전송
비디오를 전송하는 방식에는 CBR, VBR 2가지 방식이 있습니다.
1) CBR (Constant Bit Rate)
비디오가 인코딩되는 속도를 고정시킨 방식 입니다.
2) VBR (Variable Bit Rate)
비디오 인코딩 속도가 spatial / temporal 방식에 따라서 데이터 전송 속도가 계속 변경되는 방식 입니다.
인코딩에 표준에는 다음과 같이 MPEG1 / MPEG2 / MPEG4 인코딩 방식이 있습니다. 수학적인 방식에 의해서 압축률이 점차 좋아지고 있습니다.
3-3. 저장된 비디오 스트리밍
비디오 서버에는 압축된 영상의 비디오가 저장되어 있습니다. 압축된 영상의 비디오는 인터넷을 통해 클라이언트에게 전달됩니다. 이 때 네트워크 상황은 좋을 수도 안 좋을 수도 있습니다. 이런 가변적인 상황에서 비디오를 끊김없이 보낼 수 있는 알고리즘이 없을까에 대해서 연구가 진행이 되었습니다.
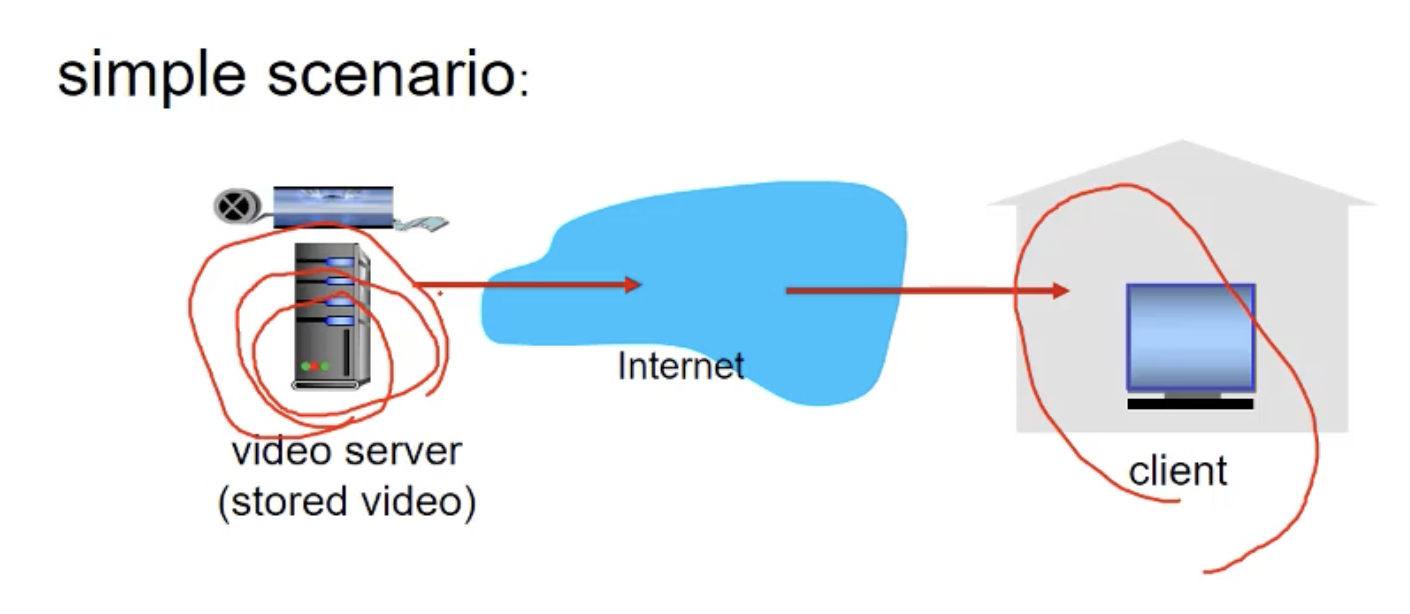
그렇게해서 채택된 스트리밍 알고리즘을 DASH라고 합니다.
Dynamic Adaptive Streaming over HTTP
HTTP라고 쓰인 이유는 대부분의 비디오 스트리밍이 웹 기반으로 전송이 될 것이다라는 전제 하에 HTTP 프로토콜을 활용해서 비디오를 효과적으로 전송하는 프로토콜을 만든 겁니다. (DASH 프로토콜 == 애플리케이션 레이어 프로토콜)
이 프로토콜은 유튜브 등 대부분의 비디오 스트리밍 서비스에서 사용되고 있습니다.
어떻게 동작하나요?
SERVER는 이렇게 동작합니다.
1) 서버가 비디오 파일을 여러개의 청크로 쪼개놓습니다.
2) 각 청크들이 다른 버전으로 서버에 저장이 됩니다. 서로 다른 인코딩 rate로 인코딩된 청크들이 서버에 저장이 됩니다. (고화질/중화질/저화질 등 8개가 넘는 상태로 저장이 됩니다.)

3) 각 청크들은 URL을 갖게 됩니다.
4) URL 정보들을 청크 별로 모두 묶어 manifest 파일을 만들어 서버는 가지고 있습니다.
client는 이렇게 동작합니다.
1) manifest 파일을 서버로부터 받습니다.
2) 주기적으로 서버와 클라이언트 사이의 bandwidth를 측정합니다. 즉, throughput을 측정한다는 의미입니다. (네트워크 속도 측정)
3) manifest 파일을 참고해서 매 시간마다 청크를 요청합니다. 1번청크 (저화질) -> 2번청크 (고화질) -> 3번청크 ...
이 때 측정한 bandwidth가 끊김없이 재생할만한 속도의 사이즈의 인코딩 버전을 선택하게 됩니다.
3-4. DASH 프로토콜의 특징
intelligence를 클라이언트에 넣었다는 것이 큰 특징입니다.
왜냐하면
1) 결국 클라이언트가 bandwidth를 측정하고, 그것을 가지고 어떤 encoding rate로 청크를 받을지 결정해서 HTTP 리퀘스트를 보내고,
2) 서버가 여러개 분산배치되어있다면 어떤 서버에 있는 청크를 요청할지
3) 버퍼를 기반해 청크를 언제 요청할지
이런 들을 요청하는 주체가 모두 클라이언트이기 때문입니다.
서버의 일은 최소화하고, 클라이언트가 결국 최적의 스트리밍을 할 수 있도록 합니다.
비디오를 끊기지 않고 보려면 버퍼를 어느정도 채울까에 대한 연구를 하는 중입니다.
이 때 버퍼를 왕창 채우면 되지 않냐고 하시는 분들이 있는데, 유튜브의 경우 끝까지 보지 않는 사람들이 있습니다. 2~3초 보고 넘기는 영상에 버퍼를 이미 채워넣으면 그만큼 네트워크 낭비가 됩니다. 또한 LTE요금을 쓰면 요금 낭비도 될 것 입니다.
4. CDNs (Content Distribution Networks)
컨텐츠를 수백만명에게 전송을 해야하는데 하나의 싱글 서버로는 당연히 커버가 불가능합니다. 아래와 같은 문제점이 발생하기 때문입니다.
1) single point of failure
2) point of network congestion : 과부하
3) long path to distant clients : 여러 지역과 서버의 거리가 멀어짐
4) mutiple copies of video sent over outgoing link : 여러 유저들에게 멀티플 카피가 전송되는데 아웃고잉 링크가 보틀넥 링크가 될 수 있기 때문
애초에 싱글서버 (mega-server)는 scale 방식이 아닙니다. 때문에 우리는 distribute한 방식 CDN을 채택하게 됩니다. 분산배치된 CDN 노드에 컨텐츠의 복사본을 저장해두는 것 입니다. (CDN 서버 == CDN 노드)

1) CDN으로부터 구독자가 컨텐츠를 요청합니다.
2) 어디에 'MADMEN' 컨텐츠가 있는지 오리지널 서버 (맨오른쪽)에 물어봅니다.
3) 오리지널 서버로부터 manifest 파일을 받습니다.
4) 주변 서버에 MADMEN 컨텐츠가 있는 것을 manifest 서버를 통해 알게됩니다.
5) 가장 가까운 CDN서버로 부터 컨텐츠를 받게 됩니다.
이는 몇가지 장점이 있습니다.
클라이언트는 가장 가까운 곳에서 매드맨 컨텐츠를 보니까 빠르게 다운로드를 받아서 안정적으로 스트림 받을 수 있습니다. 오리지널 서버에서 다운받게 되면 굉장히 많은 네트워크 패스를 거쳐서 자원이 많이 사용되었을 텐데 CDN을 사용함으로써 자원을 많이 줄일 수 있었습니다. 또한 오리지널 서버의 부하도 줄일 수 있죠. 오리지널 서버는 manifest 파일만 전달하고 끝이기 때문입니다.
아무리 CDN 서버가 가까워도 congestion이 크다면 다른 경로로 컨텐츠를 받을 수 있습니다.
이런식으로 인터넷을 통해 컨텐츠를 유통하는 서비스 프로바이더를 OTT(over the top)사업자라고 합니다.
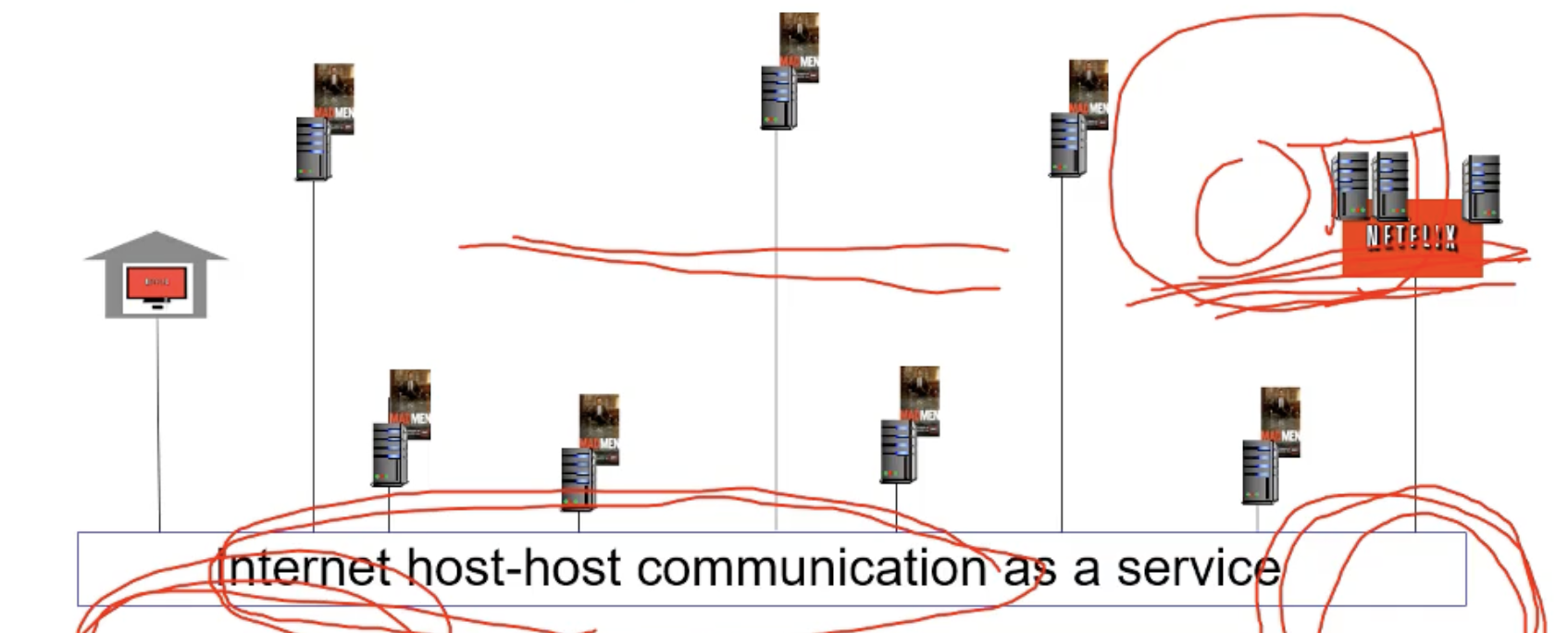
OTT 사업자가 직면한 과제로는 다음과 같습니다.
인터넷이라는 것은 안정적인 망이 아닙니다. 네트워크 상황에 따라 다르죠. OTT사업자는 콘텐츠를 안정적으로 유통을 시켜야 고객 불만을 안받습니다. 이런 해결책으로 CDN을 두었는데, 또 각 CDN 서버에 어떤 컨텐츠를 배치 시킬 것인가에 대해 고민을 하고 있다고 합니다.
또한 congestion이 발생했을 때 유저들의 행동 패턴은 어떤 식으로 변하는 가 다각도로 분석해서 고객 불만 없이 콘텐츠를 효율적으로 배포하는 노력들이 계속해서 있습니다.
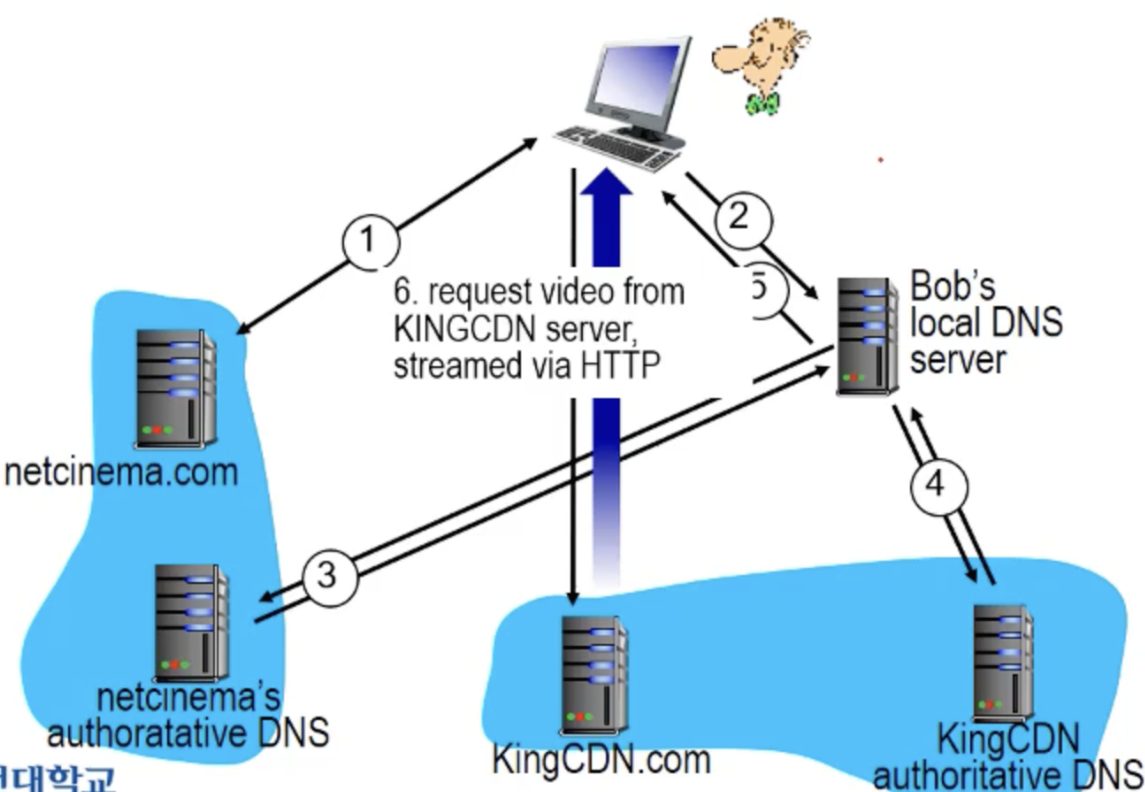
4-1. CDN 컨텐츠 엑세스
1) 밥은 넷시네마로 비디오를 받을 때 오리진 서버로 부터 URL을 얻어냅니다.
2) URL을 통해 비디오 서버에 접근해야 하는데 IP주소가 필요합니다. 때문에 DNS서버에 접근해서 IP주소를 얻어냅니다.
3) IP주소를 통해 넷시네마의 authoratative DNS 서버에 접근해서 최종 IP주소를 얻어냅니다.
4) 실제 CDN 서버에 DNS 서버를 알려주고 CDN 서버의 DNS 서버를 통해서 비디오를 받게되는 사람의 IP주소를 얻게 됩니다.
5) CDN IP주소를 통해서 HTTP 통해서 비디오 스트리밍을 받게 됩니다.
4-2. 넷플릭스 예시

1. 밥은 넷플릭스 어카운트를 가지고 있습니다. 넷플릭스 등록을 한 후 넷플릭스 서버에 접근을 합니다.
2. 밥이 넷플릭스 비디오를 보려고 합니다. 넷플릭스는 아마존 클라우드를 활용하고 있어 아마존 클라우드에 있는 넷플릭스 서버에 접근을 해서 요청할 비디오에 대한 manifest 파일을 얻어냅니다.
3. manifest 파일에는 밥이 접근할 CDN 서버를 알려주게 됩니다.
4. 여러개 CDN 서버 중에서 현재 밥이 가장 네트워크 상황이 잘나오는 CDN서버에 접근해 DASH 스트리밍을 통해 밥의 상황에 최적의 청크들을 요청받으면서 비디오를 받게 됩니다.
드디어 정리가 끝났네요 ㅠㅠ
너무나 길었던 1시간 반이었습니다 ㅎㅎ..헤헤
'CS > 컴퓨터 네트워크' 카테고리의 다른 글
| 컴퓨터 네트워크 9-2일차 : 신뢰 높은 데이터 전송, rdt 버전 (0) | 2021.09.29 |
|---|---|
| 컴퓨터 네트워크 9-1일차 : transport layer, UDP, (de)multiplexing, TCP (0) | 2021.09.29 |
| 컴퓨터 네트워크 7일차 : HTTP 프로토콜, 쿠키, 웹캐시, 이메일, DNS (0) | 2021.09.25 |
| 컴퓨터 네트워크 6일차 : 어플리케이션 구조, 소켓, 어플리케이션 레이어 프로토콜, HTTP connection (0) | 2021.09.22 |
| 컴퓨터 네트워크 5일차 : Throughput, Layering, ISP, Network Security (0) | 2021.09.14 |