

1. Network layer
1-1. 네트워크 레이어 2가지 계층
네트워크 레이어에서는 2가지 계층을 다루게 됩니다.
전송계층(data plane)은 실제 데이터가 날라가는 기능을 담당하는 부분이고, 제어계층(control plane)은 데이터가 원활하게 잘 전달되도록 제어메세지들을 다루는 부분입니다. 이 둘은 서로 유기적으로 맞물려 돌아갑니다.
예를 들어 라우터의 경우 이 데이터가 어떤 경로로 가야하는지가 결정이 되어야합니다 라우터에 데이터가 오면 아웃풋 3번 포트로 가야하면 전달이 되겠죠. 이 과정을 data plane이라 합니다. end to end를 따라 라우팅 알고리즘이 돌아가는 과정을 control plane이라고 합니다.
1-2. 네트워크 계층 : segment -> datagram encapsulation
리시버 호스트에다가 segment를 전달할 때 sending 측에서 segment를 datagram으로 encapsulation(캡슐화하다) 합니다. segment가 트랜스포트 레이어에서 네트워크 레이어로 보내는 데이터 이름을 segment라고 합니다. TCP, UDP 레이어에서 데이터를 segment라고 부릅니다. 네트워크 레이어에서는 이 데이터를 datagram이라고 부릅니다. 트랜스포트 레이어에서 데이터가 datagram으로 인캡슐한다는 뜻은 자세하게는 트랜스포트레이어에서 네트워크레이어로가면 레이어로 가면 헤더가 붙는데, 그런 과정을 은유적으로 캡슐화하는 것처럼 보인다고 하는 것입니다.
리시버 측에서는 센더 측과 반대로 네트워크 레이어에서 트랜스포트 레이어로 데이터를 올려줄 겁니다. 네트워크 레이어는 모든 호스트에서 구현이 되어야 합니다. 왜냐하면, 네트워크 레이어의 주요 기능이 라우팅이기 때문에 데이터가 전달되는 모든 노드에서 반드시 구현되어야 합니다. 센더와 리시버 사이로 데이터가 가면서 수많은 라우터들을 만날 텐데 그 라우터에 반드시 네트워크 레이어 기능이 탑재가 되어있어야 end to end로 돌아갈 수 있는 겁니다.
라우터의 기능 : input링크에서 output링크로 datagram을 라우팅 알고리즘을 통해 특정 링크로 forwarding 해준다.

트랜스포트 레이어의 핵심 기능은 end to end 즉 센더와 리시버 사이의 안정적인 전송 입니다. 라우팅이 어떻게 되는지는 트랜스포트 레이어의 일이 아니므로 해당 계층에서는 구현할 필요가 없습니다. 라우팅은 네트워크 레이어가 담당하기 때문이죠. 때문에 트랜스포트 레이어에서는 loss, congestion 유발 없이 데이터를 잘 가게하는 방법에 집중해 설계되었습니다. 즉, 트랜스포트 레이어는 모든 라우터에 탑재되지 않아도 됩니다. 중간에서 라우팅만 해주면 되기 때문입니다. 중간 노드에서 라우터가 윈도우 사이즈를 조정한다거나 loss를 재전송해주거나 중간 라우터는 트랜스포트 레이어 기능이 구현될 필요가 없습니다.
요약 : 모든 라우터는 트랜스포트 레이어 기능이 구현될 필요가 없다. 중간 라우터의 경우 윈도우 사이즈 조정, loss 재전송만 해주면 되기 때문이다. 반면 모든 라우터에 네트워크 레이어 기능은 구현되어야 한다. 왜냐하면 네트워크 레이어의 주요 기능이 라우터이기 때문이다.
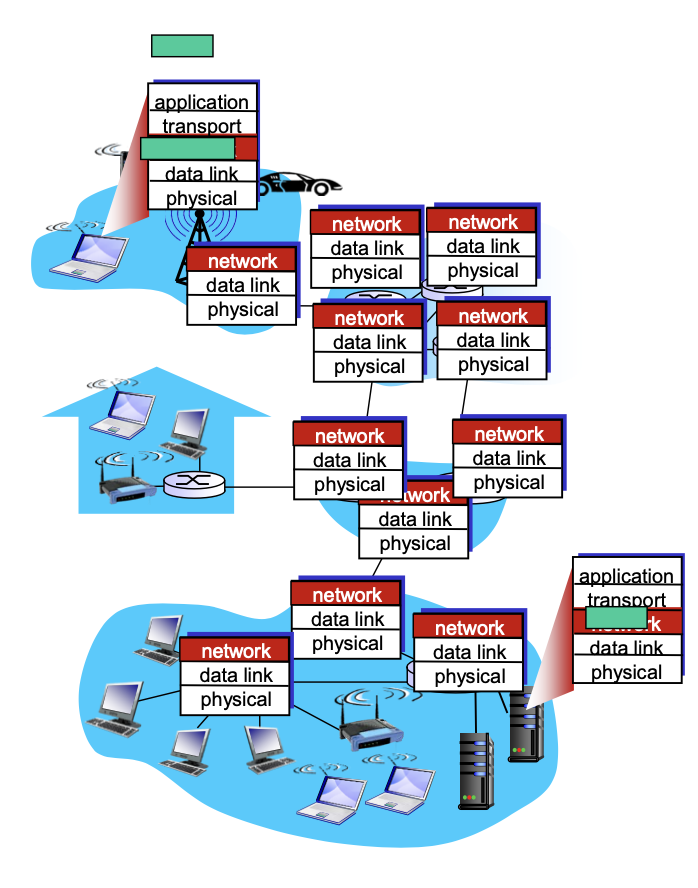
센터와 리시버는 5계층이 모두 구현되어야 작동합니다. 근데 중간에 라우터 노드는 네트워크 레이어까지만 구현이 됩니다.
실제로 라우터가 어플리케이션 레이어까지 구현된다하면 큰 문제입니다. 네트워크 레이어는 헤더의 정보를 보고서 라우팅을 했는데 중간 라우터가 어플리케이션 레이어까지 구현되어 사용자의 어플리케이션 레이어까지 볼 수 있다고 하면 범죄이기도 해서 절대 안됩니다. 때문에 어플리케이션 레이어는 end to end에서만 확인이 되어야 합니다.
1-3. forwarding
input 포트에서 들어온 데이터를 output 포트로 맵핑해주는 것을 forwarding이라고 합니다. 라우터의 로컬 액션이죠.
전달은 포워딩 테이블을 보고 수행이 됩니다.
1-4. forwarding table
라우팅 알고리즘의 output이 되는 것이 포워딩 테이블입니다. 라우팅 알고리즘이 돌아간 결과라고 볼 수도 있습니다.

포워딩 테이블은 header value와 ouput link가 맵핑되어 만들어져 있습니다. 0100 패킷은 3번 아웃풋 링크로 전달하면 되는거죠.
실제 라우터는 50~100개가 연결되어 있다고 하네요 ^^
라우터는 고속 기기인데, 느리면 큐잉이 되서 congestion이 쉽게 발생이 될 겁니다.
추가로 라우터라는 장비를 전세계에서 가장 많이 판 회사는 시스코(미국, IP 기반의 네트워크)입니다.
요즘은 범용 pc, 소프트웨어 기능이 향상이 되어 비싼 라우터를 사지않고, 소프트웨어로 라우팅 기능을 구현해 돌리면 되는 것 아니냐라는 의견이 나오고 있습니다. PC에다 라우팅 기능을 올리면 포폴로지를 유연하게 바꿀 수 있습니다. 이런 SDN 기술을 보편화된 기술로 요즘은 받아드리고 있습니다.
2. 라우팅 프로토콜

각각의 라우터는 라우팅 알고리즘이 돌아가는데 라우터 안에서 혼자 돌아가는 알고리즘이 아닙니다. 서로 다른 라우터와 유기적으로 작동하여 라우팅 패스를 알아냅니다. 때문에 라우터들끼리 정보를 주고받을 프로토콜이 필요할 겁니다. 프로토콜을 주고 받으며 라우팅 패스를 알아내겠죠. 그럼 포워딩 테이블 형태로 도출이 되어 포워딩을 진행하게 됩니다.
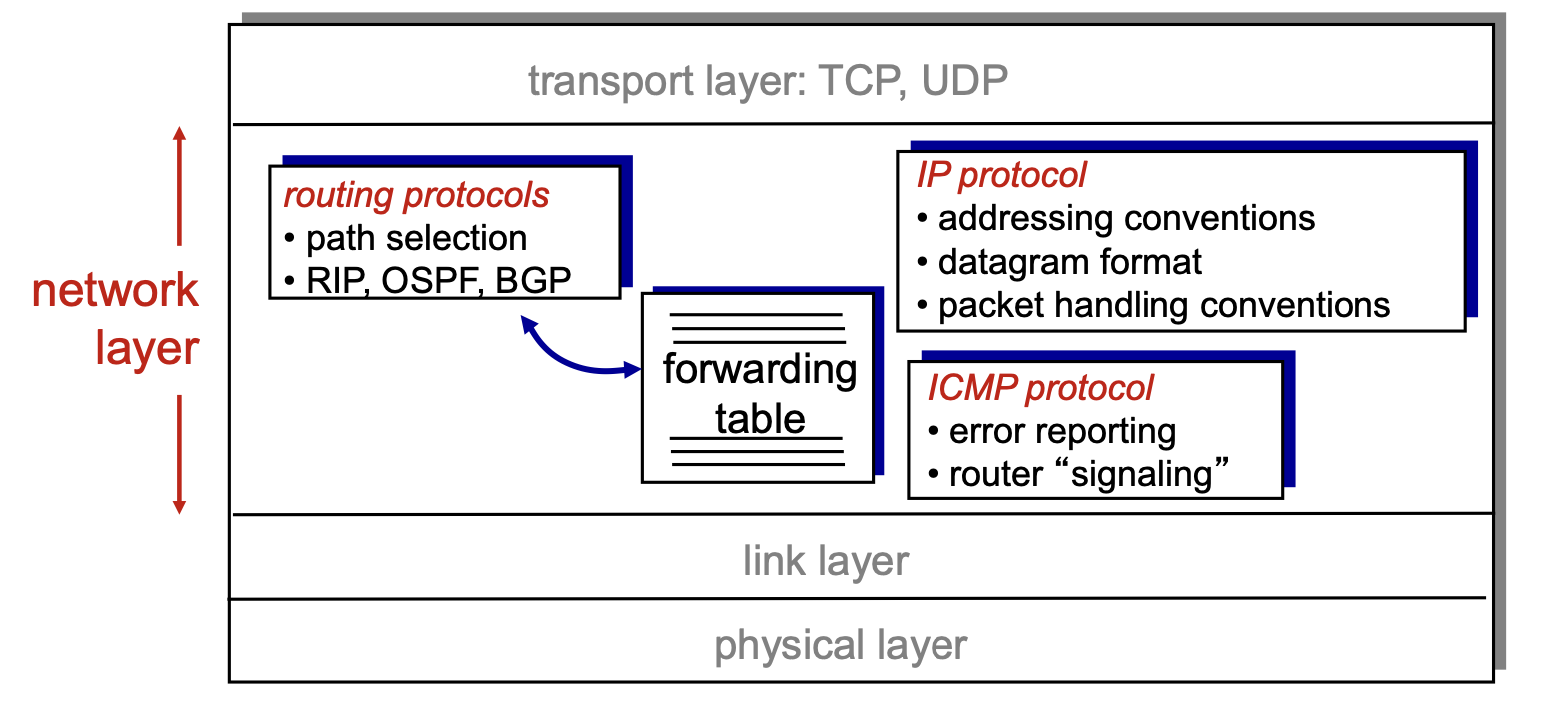
라우터는 IP 주소를 가지고 라우팅을 합니다. IP 주소 체계가 먼저 정의가 되어야 합니다. 우리나라 주소 체계는 넓은 곳에서 좁은 곳으로 갑니다. 미국은 반대입니다. 나라마다 주소체계가 좀 다른데요. 인터넷에선 이 주소 체계가 다르면 네트워킹이 안됩니다. 때문에 IP주소 체계로 통일을 하고, 프로토콜 형태로 네트워크 레이어에서 정의가 됩니다. 라우팅 프로토콜도 네트워크 레이어에서 정의가 됩니다.
네트워크의 오류 상황을 체크하기 위한 모니터링 프로토콜로 ICMP 프로토콜도 정의되어 있습니다.
웹 어플리케이션 프로토콜 : HTTP
메일 주고받는 프로토콜 : SMTP
IP 주소 알아내는 프로토콜 : DNS
reliable한 전송을 담당하는 프로토콜 : TCP
전송만 하는 프로토콜 : UDP
등 각 레이어에서는 다양한 프로토콜이 구현됩니다.
2-1. IP datagram format

IP 프로토콜 버전 정보, 헤더길이, 서비스 타입을 결정하는 type of service, 헤더와 데이터 길이를 전체 합친 length
16bit identifier, flags, fragment offset을 살펴보면, IP 데이터 그램이 링크 레이어에서 분화를 시킬 수 있습니다. 즉, 링크 레이어에서 속도가 좀 느리면 IP 데이터 그램 크기가 크면 링크 레이어에서 커버가 어려운데, 링크 레이어에 속도 맞춰 IP 데이터그램을 스플릿하게 됩니다. 리시버 단에선 스플릿하고 합칠 때 정보가 필요한데, 그게 2번째 줄입니다.
time to live (ttl)은 라우팅 알고리즘이 잘못돌아서 목적지를 못가고 정처하는 패킷, 가끔씩 고스트 패킷이 생길 때 무한 로프를 돌면서 전세계 라우터를 떠돌아 다닐 수 있습니다. 네트워크 입장에선 오버 헤드이기 때문에 없애주기 위해 ttl로 몇 hop 이상이면 버려라라고 하는 정보를 담고 있습니다.
ex) ttl=10 내가 거쳐가는 라우터가 10개 이상이면 데이터를 버려라
upper layer는 상위 계층 레이어를 기록합니다. 상위 계층 레이어에서 TCP를 쓰면 TCP라고 기입이 됩니다.
header checksum은 오류 판별을 위한 것입니다.
가장 중요한 정보는 source IP 주소, destination IP 주소 입니다.
2-2. IP flagmentation/reassembly + MTU

flagment는 파편화하다 라는 의미입니다. reassembly는 파편화한 걸 다시 합치는 과정을 말합니다.
링크 레이어에서 사용하는 기술은 다양합니다. wifi, 이더넷, 5G 등이 모두 링크 기술이죠. 이렇게 링크마다 속도가 다르기도 합니다.
각 링크 기술이 커버할 수 있는 최대 데이터 사이즈를 MTU(max.transfer size)라고 합니다. 링크가 굉장히 빠르면 MTU가 크고, 링크 속도가 느리면 MTU가 작게 표시되어 있습니다. 참고로 이더넷은 1500B로 MTU를 정의하고 있습니다.
상위 계층, 네트워크에 ip datagram이 MTU가 클 수 있습니다. 크면 쪼개서 MTU를 맞춰줘야하는데 이것을 flagmentation이라고 합니다.
이는 마지막 목적지에서 다시 reassemble 되어 하나의 IP datagram으로 만든다. 이렇게 쪼개고 합치는 기능을 지원하기 위해 IP헤더는 여러가지 부가정보를 2번째 줄에서 제공하고 있습니다. (16bit identifier, flags, fragment offset)

만약 4000byte datagram(실제데이터 3980, 헤더 20)이 있다면, MTU가 1500바이트이면 위의 이미지와 같이 3개로 flagmentation이 됩니다. length에는 헤더 사이즈(20바이트)+데이터이기 때문에 함께 포함이 되어있습니다.
fragflag=1이라는 뜻은 내 다음에 붙어야 할 다음 조각이 1개 있다는 의미입니다.
offset은 내가 어디에 위치하는지를 알려줍니다. 0부터 시작, 185부터 시작, 370부터 시작이라는 의미입니다.
이전 length-20에서 8로 나눈 값을 offset으로 채용합니다. (1500-20)/8
ID는 3개의 fragment가 동일한 데이터그램이라는 정보를 나타내줍니다.
이렇게 fragmentation하면 안좋은 점은 헤더가 1개에서 3개로 늘어나니 overhead가 늘어난다는 점이 안좋은 점입니다.
3. IP4 addressing
3-1. interface
LAN카드, 이더넷포트 등을 인터페이스라고 합니다. 호스트 라우터와 피지컬 링크 사이의 연결점입니다.
호스트가 링크랑 연결하기 위한 네트워크 카드가 있을텐데 이것을 인터페이스라고 합니다.

라우터는 여러 링크를 연결시켜주는 역할을 하기 때문에 굉장히 많은 인터페이스를 가지고 있습니다. 아래 구멍들이 전부 인터페이스가 되는 겁니다.
'CS > 컴퓨터 네트워크' 카테고리의 다른 글
| 컴퓨터 네트워크 19일차 : 라우터 기능, 방화벽 (0) | 2021.11.09 |
|---|---|
| 컴퓨터 네트워크 18일차 : IP addressing, DHCP, NAT (0) | 2021.11.06 |
| 컴퓨터 네트워크 16일차 : TCP congestion control (0) | 2021.10.31 |
| 컴퓨터 네트워크 14일차 : fast retransmit / flow control / connection management (0) | 2021.10.18 |
| 컴퓨터 네트워크 13일차 : TCP/IP, ACK time out 시퀀스넘버 (0) | 2021.10.13 |