

오늘은 고가의 장비 라우터에 대해 알아보겠습니다 : ) 라우터에서 포워딩을 하려면 당연하게 포워딩 테이블이 준비되어 있어야 합니다. 포워딩 테이블은 바로 라우팅 알고리즘에 의해서 만들어 집니다. 일단은 포워딩 테이블이 있다고 가정하고, 어떻게 포워딩이 이뤄지는지 알아보도록 하겠습니다.
1. 라우터 핵심기능
라우터에서 제공하는 2가지 핵심기능이 있습니다.
첫번째 기능으로는 라우팅 알고리즘을 수행합니다. 라우팅 알고리즘을 지원하기 위한 프로토콜도 존재합니다.
두번째 기능으로는 라우팅 알고리즘에 의해서 도출된 포워딩 테이블을 기반으로 실제 포워딩을 지원합니다.

위의 그림에서 점선은 control plane(위)과 data plane(아래)을 나눠주는 점선입니다.
1-1. routing processor
control plane에는 라우터 프로세서가 탑재되어 있습니다. 라우터 프로세서는 프로토콜을 동작시키고, 그 기반으로 알고리즘을 동작시켜, 포워딩 테이블을 계산합니다.
또한 이 부분은 routing management plane라고 합니다. 소프트웨어적인 부분입니다. 밀리세컨드 타임 프레임으로 동작해요.
프로세서에서 나온 포워딩 테이블은 dataplane으로 넘어가게 됩니다.
1-2. data plane
포워딩 테이블은 각각의 인풋포트로 전달이되게 됩니다.
인풋포트는 포워딩 테이블을 load 한 다음, 들어오는 데이터그램을 어떤 아웃풋 포트로 보낼지를 판단하고 전달합니다.
데이터를 전달하는 time scale은 나노프레임 타임 프레임으로 동작합니다. (밀리세컨드보다 더 빠른 스케일)
즉, dataplane은 하드웨어적인 부분이 좀 더 중요한 부분입니다.
input port에서 진행되는 과정들

먼저, 전파가 라우터로 들어오면 line termination 파트에서 물리계층 즉, bit level로 데이터를 받습니다. 이게 맥 레이어로 올라가고, 링크 레이어 프로토콜을 지원하는 부분이 있습니다.
네트워크 계층에서 lookup 즉, 포워딩 테이블을 살펴보는 파트가 여기입니다. 포워딩 테이블을 살펴본 후 어떤 링크로 보내야하는지 판단하고 보냅니다.(연산시간 유) 실제 연산이 많이 일어나는 부분은 이 파트 입니다.
실제 큐잉은 output포트에서 많이 일어납니다.
패킷이 들어오면, 아웃풋 링크로 밀어줘야하는데 link capacity 이상으로 못 밀어넣어서 output에서 큐잉이 생기게 됩니다. 큐가 꽉차게 되면 packet loss까지 발생하게 되는 것이죠.
아웃풋 포트를 destination 주소를 기반으로 해서 계산합니다. 포워딩 테이블이 로드가 되어있고, 그 후 목적지 IP가 어딘지 매치하게 됩니다. 이것을 좀 어려운 말고 destination-based forwarding(목적지 주소를 기반해서 포워딩 한다) 이라고 합니다. 이것을 아래 그림으로 다시 이해해보도록 하겠습니다.

IP 헤더를 살펴보면, 다음과 같은 포워딩 테이블이 로드가 되어있을 것입니다. 포워딩 테이블은 control plane의 알고리즘에 의해 연산이 된 것입니다. 그 후 destination 주소는 어떤 범위의 포함이 되는지 확인합니다. 그리고 포함되는 범위에 해당하는 output link로 포워딩이 되게 됩니다.
1-3. destination 주소 : 포워딩 테이블은 왜 범위로 만들어질까?

destination 주소는 이론적으로 2^32이 존재할 수 있습니다. 이 수많은 주소를 일일히 매칭해서 몇 번 포트로 보낼지 판단하는 것은 연산시간이 너무 오래 걸릴 것입니다. 때문에 범위로 포워딩 테이블이 만들어지게 됩니다.
이 때 이 범위는 지난시간에 배운 prefix 입니다. 서브넷에 해당하는 파트이죠.
컴퓨터 네트워크 18일차 : IP addressing, DHCP, NAT
1. IP addressing IP주소가 어떻게 할당되고, IP주소 갖는 의미에 대해서 알아보도록 하겠습니다. 우선 지난 시간 배웠던 인터페이스를 살짝 다시 들춰보겠습니다. 1-1. IP4 addressing : interface LAN카드, 이.
tksgk2598.tistory.com
1-4. prefix matching

우리는 IP주소에서 포워딩 테이블과 서브넷 주소에 해당하는 prefix 부분만 비교하면 됩니다. host 부분을 볼 필요가 없습니다. 이것을 다른말로 prefix matching이라고 합니다.
위의 3가지 예시 중 1번 IP는 0번 포트로 갈 겁니다.
2번은 서브넷에 일치하는 것이 없기 떄문에 3번으로 매칭됩니다.
3번은 1번으로 가냐 2번으로 가냐 헷갈리시 겠지만, 1번으로 매칭이 됩니다. 만약 2개가 매칭이되면, 매칭된 것 중에 더 긴 쪽을 따르기 때문입니다. 이런 법칙을 Longest prefix matching이라고 합니다.
1-5. Longest prefix matching

1번 문제는 2번에 매칭됩니다.
2번 문제는 1번 2번 둘다 매칭이 되지만, 1번이랑 더 길게 매칭되므로 1번에 매칭됩니다.
그렇다면 우리는 왜 Longest prefix matching라는 기법을 써야할까요?

Fly-By-Night-ISP(마치 KT 같은)가 아이피 주소를 돈주고 사왔다고 가정합시다. 200.23.16.0/20을 사왔습니다.
해당 주소는 2^12까지 호스트를 커버할 수 있죠.
2^12 호스트를 쪼개서 사용할 수도 있습니다. 서브넷은 유지해야만 합니다. 호스트를 조금 빼서 서브넷에 편입시키는 것은 가능합니다. 만약 8개의 서브조직이 필요하면, 2^3이기 때문에 3비트가 필요합니다. 때문에 3비트를 호스트에 편입시킨 것입니다.
대신 각 조직에선 2^9만큼의 호스트를 관리할 수 있게 되는 것 입니다.

각각의 조직들은 라우터로 구분이되고 있습니다. 왜냐하면 서브넷이 다르다는 것은 네트워크가 다르다는 것을 의미하기 때문입니다.
상위 라우터는 첫번째로 할당받은 주소로 되어 있습니다. 즉, 200.23.16.0/23으로 먼저 주소를 관리합니다. 그 후에 세부 정보를 보고 어디로 포워딩 할지로 결정하는 것입니다.
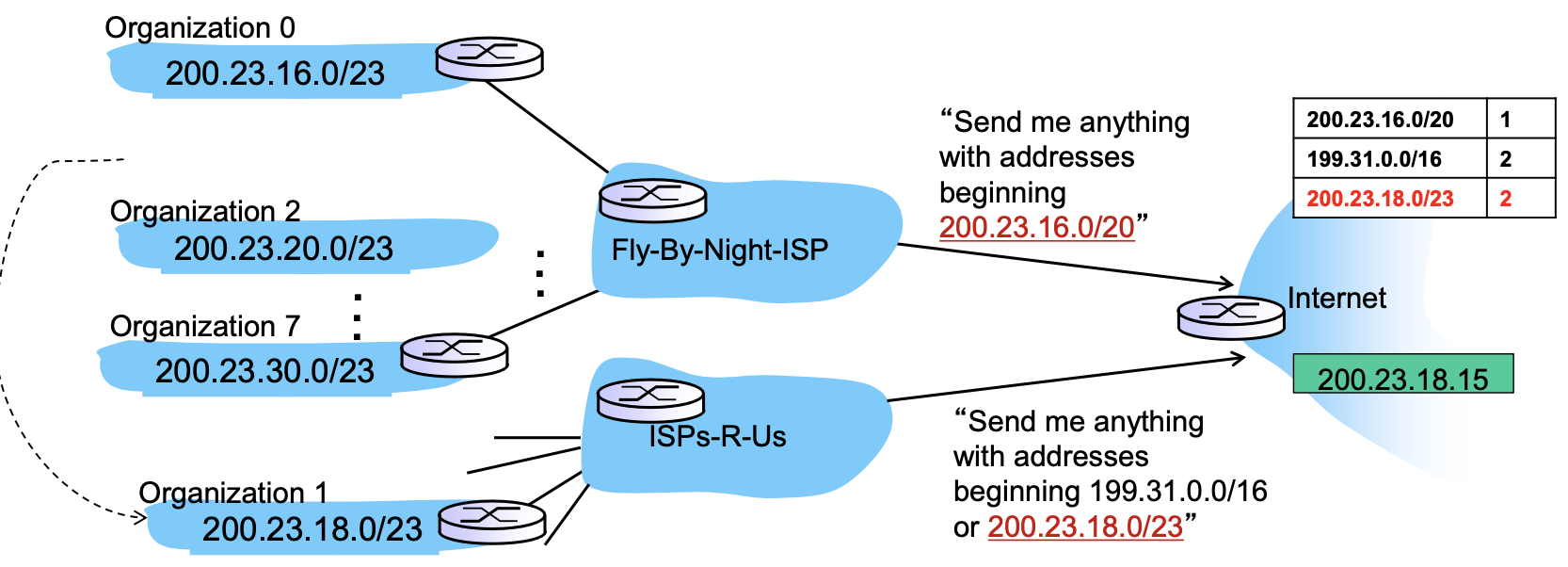
이 때 조직1이 이사를 갔다고 해봅시다. KT에서 LG로 이사간 격이에요. 200.23.18.0/23은 ISPs-R-US(like LG)로 라우팅 해달라고 알리게 됩니다. 이 때 200.23.18.15가 도착하면 문제점이 생깁니다. 문제점은 ISPs-R-US는 물론 Fly-By-Night-ISP에도 해당 주소가 매칭된다는 점입니다.
Fly-By-Night-ISP 주소 자체가 200.23.18.0/23에서 파생된 것이 때문입니다. 결과적으론 길게 매칭되는 ISPs-R-US로 포워딩되게 됩니다.
다음과 같이 중복되는 문제 때문에 Longest prefix matching이 필요합니다.
1-6. input <-> output 연결하는 3가지 방법

인풋포트와 아웃풋포트를 연결하기위한 3가지 방식이 존재합니다.
가장 고전적인 방식은 중간에 메모리를 주는 것입니다. 메모리에서 임시저장을 한 다음에 아웃풋 링크로 전달하는 방식입니다.
이와 같은 경우 메모리 자체가 굉장히 비싸고, 메모리에서 보틀넥도 많이 발생하기 때문에 포워딩 속도가 느려져서 1세대 라우터에서 많이 사용하는 방식이라고 합니다.
두번째 방식은 중간에 버스를 두는 것인데요. 버스는 고속으로 데이터를 전달할 수 있어 효율적이지만, 문제는 버스 링크를 여러 개의 인풋포트들이 쉐어하다 보니 실제로 큐잉이 발생하는 부분이 됩니다. 트래픽이 몰릴 땐 버스에서 보틀넥이 발생하게 되는 것이죠.
다음 세대 방식으로는 크로스바 방식으로 설계한 다음에 보틀넥은 상당부분 해결이 되었습니다.
이렇게 아웃풋포트로 패킷이 전달이 되면, 패킷은 버퍼에 임시로 머무른 다음에 링크 레벨 프로토콜로 들어가 전파로 전달되게 됩니다.

데이터그램을 아웃풋 링크로 보내줘야하는데, 링크 capacity가 존재합니다. 이 link capacity보다 빠르게 내보낼 순 없어요. 못 나가는 데이터들이 큐잉되어 대기하게 되고, 버퍼가 꽉찬 상태에서 새로운 데이터그램이 들어오면 loss가 나게 되는 것입니다.

2. Firewalls

firewalls는 장벽 역할을 합니다. 어떤 조직에 내부 네트워크를 바깥에 인터넷으로부터 보호하기 위한 용도로 사용하기 위한 장비입니다. 특정 패킷은 통과해주고 특정 패킷은 통과시켜주지 않는 식으로 외부 트래픽을 차단해주는 역할을 합니다.
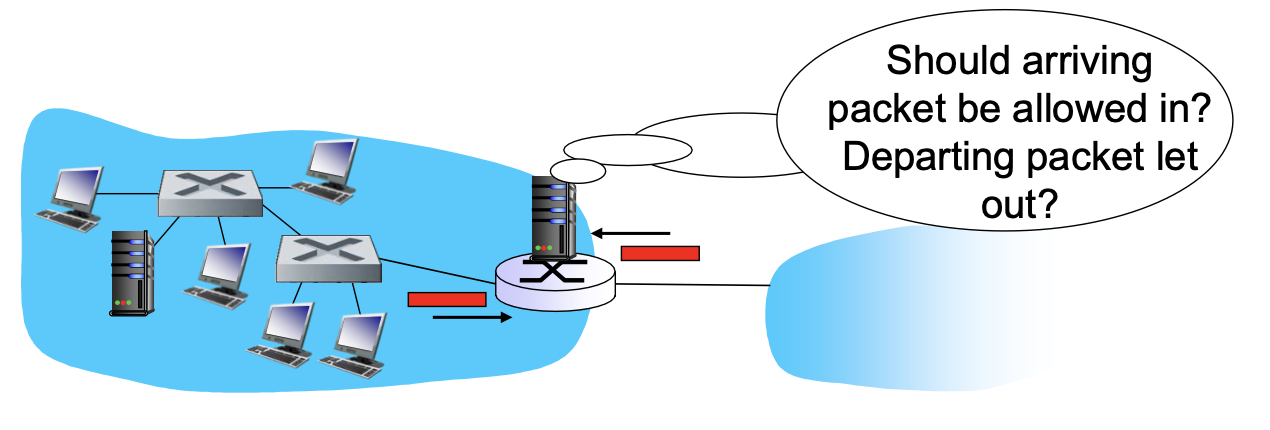
게이트웨이 방화벽이 설치되어 있는 경우가 많은데요. 게이트웨이에 firewall이 설치되면, 패킷 단위 패킷으로 보면서 통과 여부를 관리합니다. 들어오는 패킷과 나가는 패킷 모두요~!
이 때 들어오는 패킷, 나가는 패킷의 기준을 위해 룰을 만들게 되는데요.
필요한 정보로는 source IP주소&포트넘버, destination IP주소&포트넘버 이 4가지 정보를 가지고 룰을 만듭니다.
+보통 방화벽은 HTTP 80포트를 막는 경우가 많은데요. 웹 트래픽이 아닌 것들을 많이 의심하기 때문입니다.
실제 bad 트래픽인지 아닌지는 컨텐츠를 깔아봐야 아는데 왜 이렇게 안하고 단순한 로직으로 동작할까요?
1) 일단 컨텐츠는 어플리케이션 계층에서 전부 암호화되어 전달됩니다. 정보는 종단 호스트 밖에 못보는 것이죠. 때문에 중간에서 방화벽이 정보를 보는 것은 사실상 힘듭니다.
2) 만약에 암호화가 안된 트래픽들도 존재할텐데, 어플리케이션 데이터를 패킷 바이 패킷으로 검증하면서 필터링하면 firewall에서 엄청 느려지겠죠. 실질적으로는 방화벽에서 볼 수 있는 정보를 빠르게 보고 판단해야하기 때문에 단순한 정보로 필터링해야하는 한계가 있습니다.
2-1. firewall의 또 다른 쓰임새
중국 firewall은 전세계의 firewall을 전부 등록해두었습니다. 그말은 즉슨 만약 중국에서 firewall에 유튜브, 페이스북 등을 등록한다면 해당 앱을 쓸 수 없다는 말입니다.
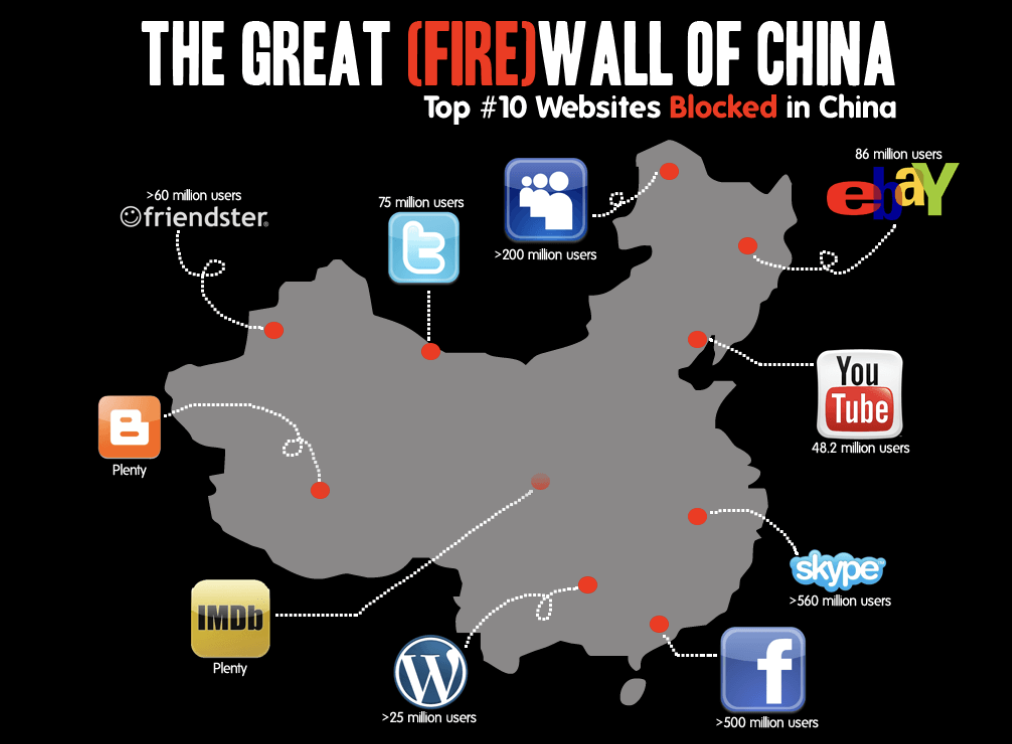
그렇다면 중국 정부에서 firewall으로 막는 이유는 무엇일까요?
유튜브 같은 경우는 미국 문화가 많은데, 중국 체제 성립에 있어서는 방해가 될 수도 있기 때문에 외부의 문화를 막기위한 목적도 있을 겁니다. 중국은 표면적으로는 그건 아니다라고 주장하고 있죠.
또 다른 목적은 중국에 내수시장이 엄청 크기 때문에 중국전용 사이트/앱을 만들면 세계 최고 사이트/앱을 만들 수 있습니다. 즉, 내수 소프트웨어 산업을 키우기 위해서 firewall을 하기도 합니다. 무역 공정 거래 입장에선 예민한 입장이죠 : )
3. Middleboxes

네트워크를 구성하는 가장 기본적인 장비는 라우터입니다. 하지만 이후에 기타 네트워크 장비를 middle box라고 합니다. NAT, firewall, load balancer, 터널링 장비 등 많은 네트워크 장비들이 있습니다.
+한국은 미들박스 장비를 만드는 데 있어서 강국이었습니다. 라우터는 사실상 시스코가 전세계 장악했고, 우리나라에선 중소기업들이 기타 네트워크 장비를 잘만들어서 큰 중소기업이 많았습니다. 문제는 중국에 다 뺐겼습니다... ㅠ 중국에서 저가 제품을 풀었기 때문이죠...삼성에서는 기지국만드는 걸로 네트워크 사업부가 간신히 버티고 있다고 하네요.
미들박스가 너무 많아서 네트워크 서비스를 구축하는 사업자 입장에선 머리가 아플 수 밖에 없습니다. 다 이해해야하고, 장비 다 설치/유지보수 해야하는 게 어려워서요. 때문에 이런 장비들을 소프트웨어 기반으로 할 수 없을까 고민하게 됩니다. 우리는 이것은 SDN(Software Defined Networking)라고 합니다.
4. SDN(Software Defined Networking)
10년 넘게 연구레벨에 머물렀습니다. 네트워크 장비들이 고속의 패킷을 처리하는 일들을 하다보니 일반 범용 PC에서 다루는 데에는 어렵기 때문입니다. 소프트웨어도 일반 범용 PC 소프트웨어로 구동하기 어렵다는 시각이 많았습니다.
하지만, 소프트웨어 기술이 좋아지며, 더이상 네트워크 장비들이 네트워크 장비 회사들의 전유물이 아닌 소프트웨어 회사들의 차례가 온 것이죠.
4-1. 소프트웨어적으로 어떻게 동작할까?
2가지로 표현이 가능합니다. match하고 action입니다.
match는 포워딩 테이블에서 IP주소를 매칭합니다.
action은 포워딩하는 것이 액션이에요.
firewall에서는 어떨까요?
match는 룰을 기반해 어떤 IP, PORT 정보를 받아라 하는 것이 매치입니다.
action은 이 패킷을 통과시켜라가 액션입니다.
대부분의 장비들은 match와 action으로 표현이 가능합니다.
OpenFlow1.0에서는 match와 action의 큰 틀을 제공하고 있다고 하네요.

SDN은 L2, L3을 포함한 모든 네트워크를 아우르는 것을 목적으로 만들어졌습니다. L3을 위한 기술이었다면 match라면 IP헤더라고 한정했을 겁니다. action은 포워딩하는 액션을 수행할 수 있고요 (라우터). -> 자세한 내용 위의 이미지 참고

SDN에서는 논리적으로 centralized 된 컨트롤러가 존재합니다. 컨트롤러는 flow table이라는 것을 만들어 data plane 역할을하는 장비에다가 내려주는 역할을 하게 됩니다. 각각의 라우터는 flow table을 받아서 flow table을 수행하게 되는 겁니다.
flow table이 라우팅 기능을 정의한다면 flow table을 받은 장비는 라우터가 되는 것이고 firewall 기능을 정의한다면 장비는 firewall이 되는 겁니다.
SDN 파트를 정의할 때 data plane 부분은 실질적으로 서버 급 PC가 대체하진 못하고 고속의 스위치가 대체하게 됩니다.
control plane 부분은 고성능 서버가 대체하게 됩니다.
장점은 라우터는 수천만원에 달하는 데 고속의 스위치는 수십만원대로 가격이 쌉니다. 스위치에는 라우팅 알고리즘을 구동시키거나 하는 기능이 없고 단순 포워딩 기능만 하거든요. data plane은 아주 싼 스위치로 동작시킬 수 있습니다.
라우터는 data plane이랑 control plane이 패키지로 있는 장비이기 때문에 고가입니다.
4-2. Open Flow의 Flow Table
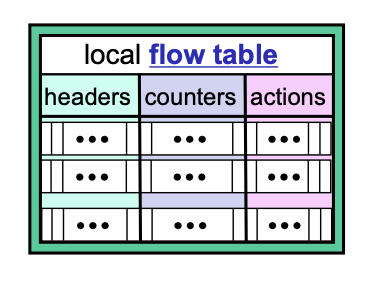
헤더 필드는 패킷의 헤더를 나타냅니다. 패킷의 헤더를 매치하는 역할을 합니다.
카운터는 flow table의 라이프 사이클을 관리하기 위한 용도로 쓰입니다. 즉, 몇 개의 패킷이 매치가 되었는지 혹은 테이블 엔트리가 언제 업데이트 되었는지와 같은 정보들을 카운터를 통해서 관리합니다. 너무 오래된 flow table은 다시 업데이트를 한다던지 expire 시킨다던지 관리합니다.
액션은 말그대로 헤더 필드를 매칭한 다음에 어떤 동작을 수행할지를 정의합니다.
3가지 필드를 담고있는 프로토콜이 오픈 플로우라는 프로토콜입니다.
오픈 플로우 프로토콜이 SDN에 구현하기 위한 가장 잘 알려진 프로토콜로 정의가 되어 있습니다.

다음 첫번째 예시와 같이 소스 주소, 목적지 주소가 다음과 같으면 드랍시켜라 라고 정의할 수도 있는겁니다. 그럼 이 친구는 일종의 firewall 역할을 할 수 있는 셈입니다.
참고로* . * . * . *의 뜻은 와일드 카드입니다. don't care~
두번째 예시는 2번 포트로 보내라 라고 정의하고 있네요.
세번째와 같이 기존엔 없던 기능들을 구현하고 추가해서 새로운 네트워킹 기능들을 구현할 수 있다는 겁니다.
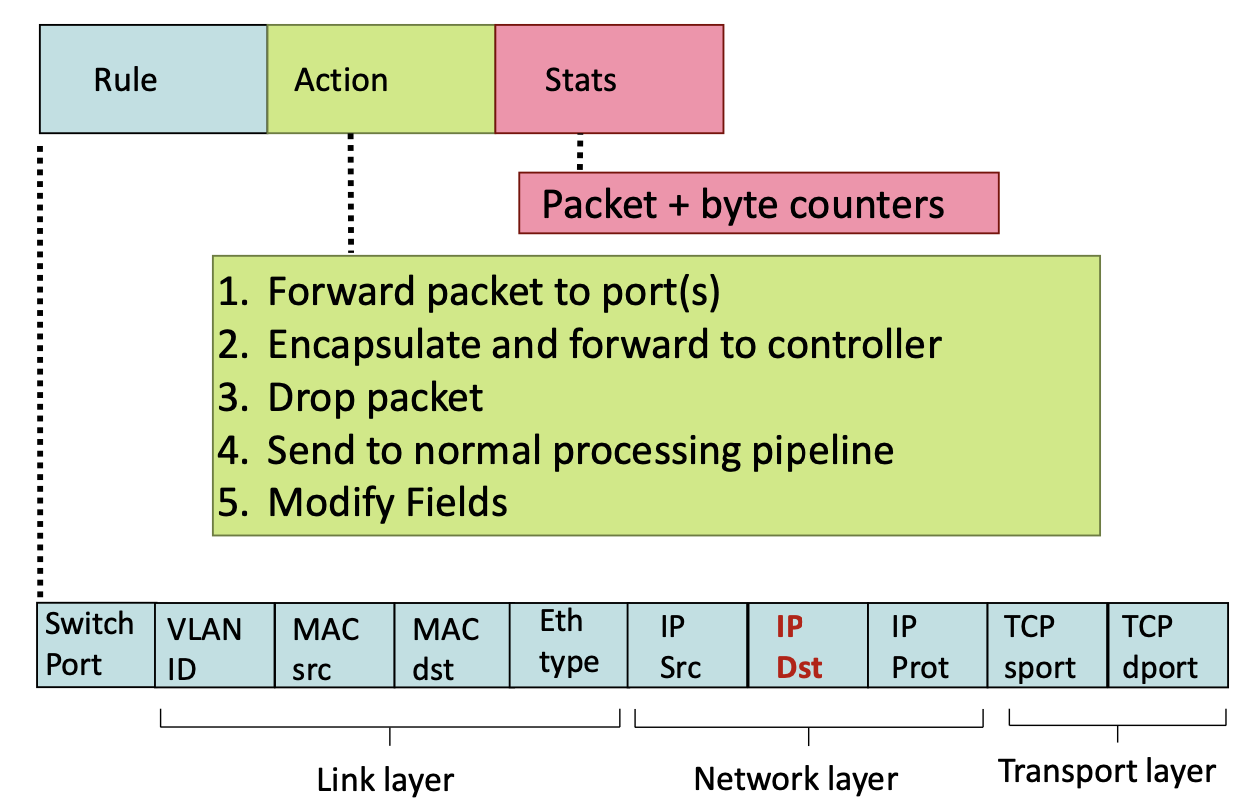
오픈 플로우는 다음과 같이 룰 액션 스테이터스의 3가지 파트로 나누어지고 액션은 말그대로 액션입니다.
룰은 헤더 정보(링크, 네트워크, 트랜스포트 레이어를 전부다 아우르는)들에서 내가 필요한 정보를 매칭정보로 사용할 수 있고, 그에 따라서 액션을 정의할 수 있습니다.
스테이터스는 플로우테이블의 라이프 사이클을 관리하는 용도로 보조적인 용도로 사용됩니다.
오픈 플로우를 적용하게되면 사업자 입장에서 policy 기반의 라우팅을하기에 굉장히 용이합니다. 지금 라우팅은 딱 정해진 라우팅 프로토콜 위에서만 규칙대로 라우팅이 되기 때문에 사업자가 임의로 라우팅 policy를 점유하고 싶을 때가 있습니다. 이 트래픽은 어떤 긴급상황이니까 이쪽 라우터로 보내고 싶다든지 등 지금은 그걸 못합니다. 왜냐하면 지금은 딱 프로토콜에 의해서 자동으로 라우팅이 되기 때문에 중간에 사업자가 폴리시를 적용해서 임의로 라우팅 경로를 바꾸는 것이 굉장히 어렵습니다.
근데 이 오픈 플로우 기반으로 하게 되면 기존에 자동으로 되던 라우팅 기능을 기본적으로하면서 어떤 예외상황이나 어떤 긴급 상황 때 새로운 규칙을 적용하기가 굉장히 쉬워집니다.
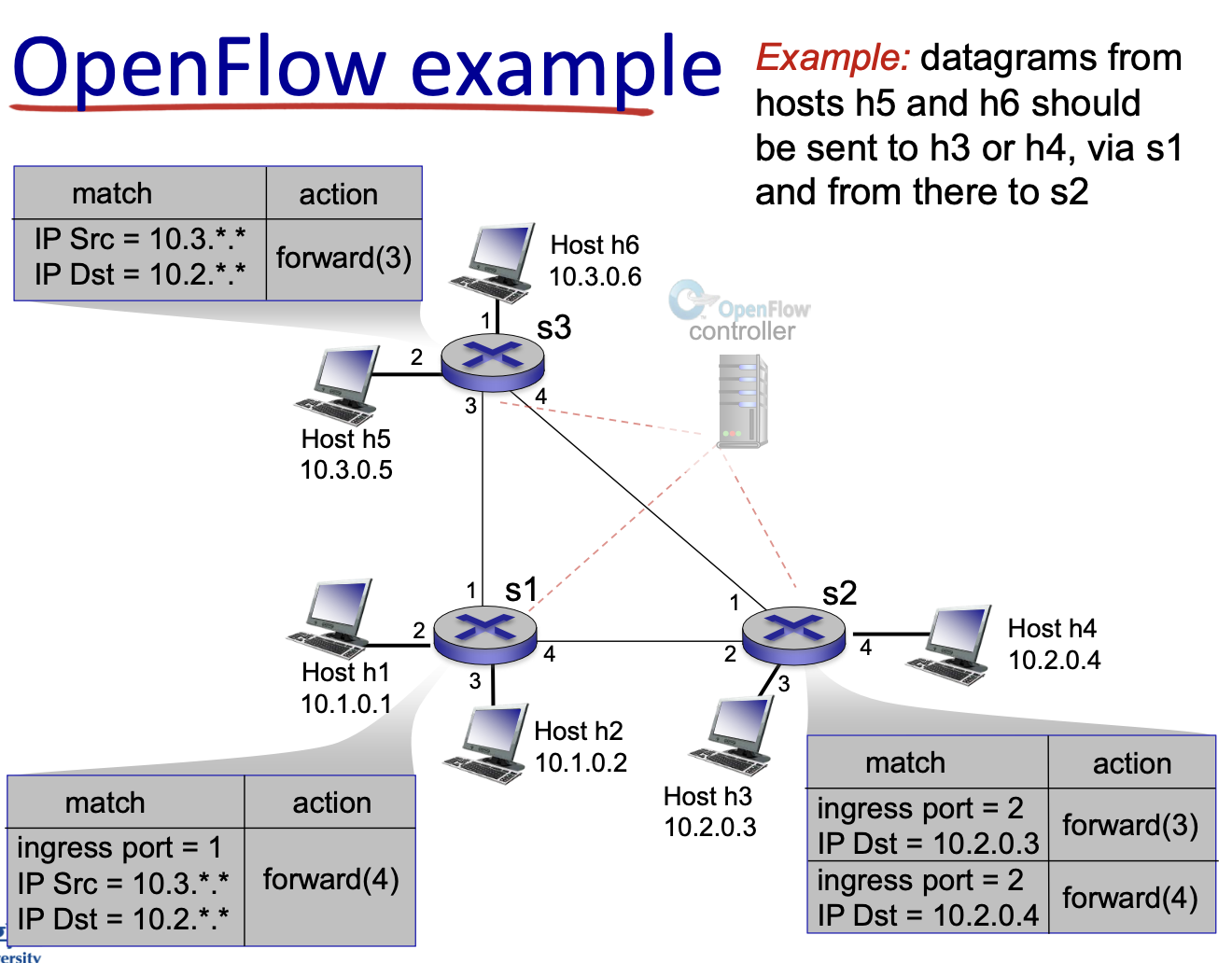
다음과 같이 호스트 5랑 호스트 6가 패킷을 보내는데 패킷이 3이랑 4의 패킷을 보내는 상황입니다. 라우팅 알고리즘에 의해서 최적의 경로로 라우팅이 될 것입니다. 최적의 경로를 사업자가 직접 컨트롤하기는 어려워요. 하지만 사업자가 "나는 이 트래픽을 전부 이쪽에 몰고 싶어 아무리 다른 곳이 좋더라고 지금은 특수한 상황이기 떄문에 가게하고싶어"라는 니즈가 생길 수 있습니다. 이럴 때 직접 configulation하여 작성하면, 소스가 10.3이고 목적지가 10.2인 경우 3번으로 포워딩해라 flow table을 내려주는 겁니다.
1번포트로 내려오는 패킷이면서 다음과 같은 IP를 가지면 4번 포트로 포워딩해라 등
최종적으로 원하는 목적지로 포워딩 할 수 있는겁니다.
지금 현재 라우팅 프로토콜은 최적의 라우팅 패스를 고르도록 설계가 되어있습니다. 가끔씩 manuary configulation하기가 굉장히 까다로운 부분이 있는데 오픈 플로우는 그런 부분도 굉장히 유연하게 구현할 수 있으니까 사업자 입장에서는 굉장히 매력적인 요소입니다.
아직 SDN 기반으로 실제 운영하는 일이 많이 확산되지 않았지만, 구글의 데이터센터 같은 경우 왜냐면 구글이 전부다 그 데이터센터의 라우팅을 통제할 수 있거든요. 때문에 SDN 기반으로 운영하고 있습니다.

1번째 같은 경우는 다음과 같은 IP주소가 들어오면 포트 6번으로 보내라라는 라우터 기능을 담당합니다.
2번째 같은 경우는 포트 번호가 22번인 경우 드랍시켜라라는 firewall 기능을 담당합니다.
마지막도 firewall 기능이네요.

다음과 같은 맥주소를 갖고 있는 3번포트로 보내라 , 이건 스위치 기능을 담당하고 있네요.

'CS > 컴퓨터 네트워크' 카테고리의 다른 글
| 컴퓨터 네트워크컴퓨터 네트워크 21일차 : Distance Vector 알고리즘(2) (0) | 2021.11.17 |
|---|---|
| 컴퓨터 네트워크 20일차 : 라우팅 알고리즘, 다익스트라 알고리즘, link state, distance vector (0) | 2021.11.16 |
| 컴퓨터 네트워크 18일차 : IP addressing, DHCP, NAT (0) | 2021.11.06 |
| 컴퓨터 네트워크 17일차 : Network layer (0) | 2021.11.03 |
| 컴퓨터 네트워크 16일차 : TCP congestion control (0) | 2021.10.31 |