
1. Distance Vector 알고리즘
벡터 알고리즘 부분 남은 부분을 진행하도록 하겠습니다.
Distance Vector 알고리즘이 어떻게 자신의 라우팅 테이블을 어떻게 업데이트하는지 그 과정을 한번 보겠습니다.
1-1. Distance Vector : Bellman-Ford equation
Distance Vector 알고리즘이 업데이트할 때 사용하는 식이 있습니다.
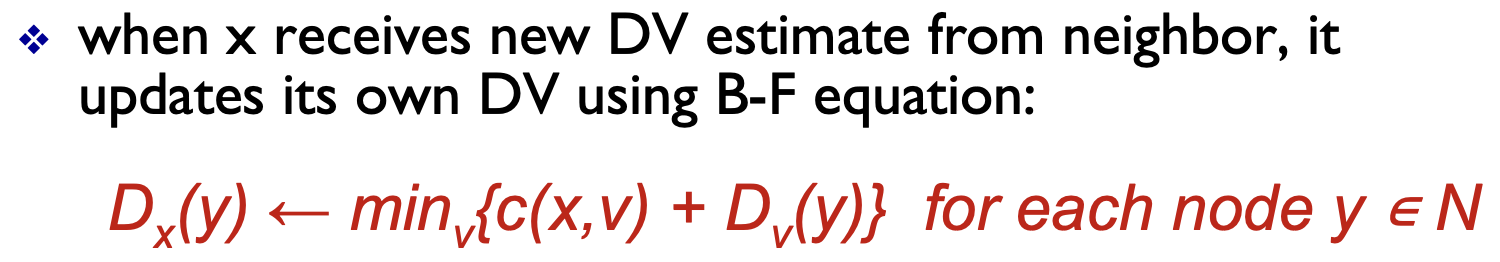
이 식을 Bellman-Ford equation(벨만 포드 이큐에이션)이라고 합니다.
근데 이게 단순히 디스턴스 벡터 알고리즘에만 사용되는 건 아니고 우리 강화 학습이나 여러 알고리즘에서 지속적으로 업데이트하기 위한 업데이트 식으로 많이 적용이 되는 이큐에이션입니다.
1-2. Distance Vector 알고리즘의 간단한 토폴로지
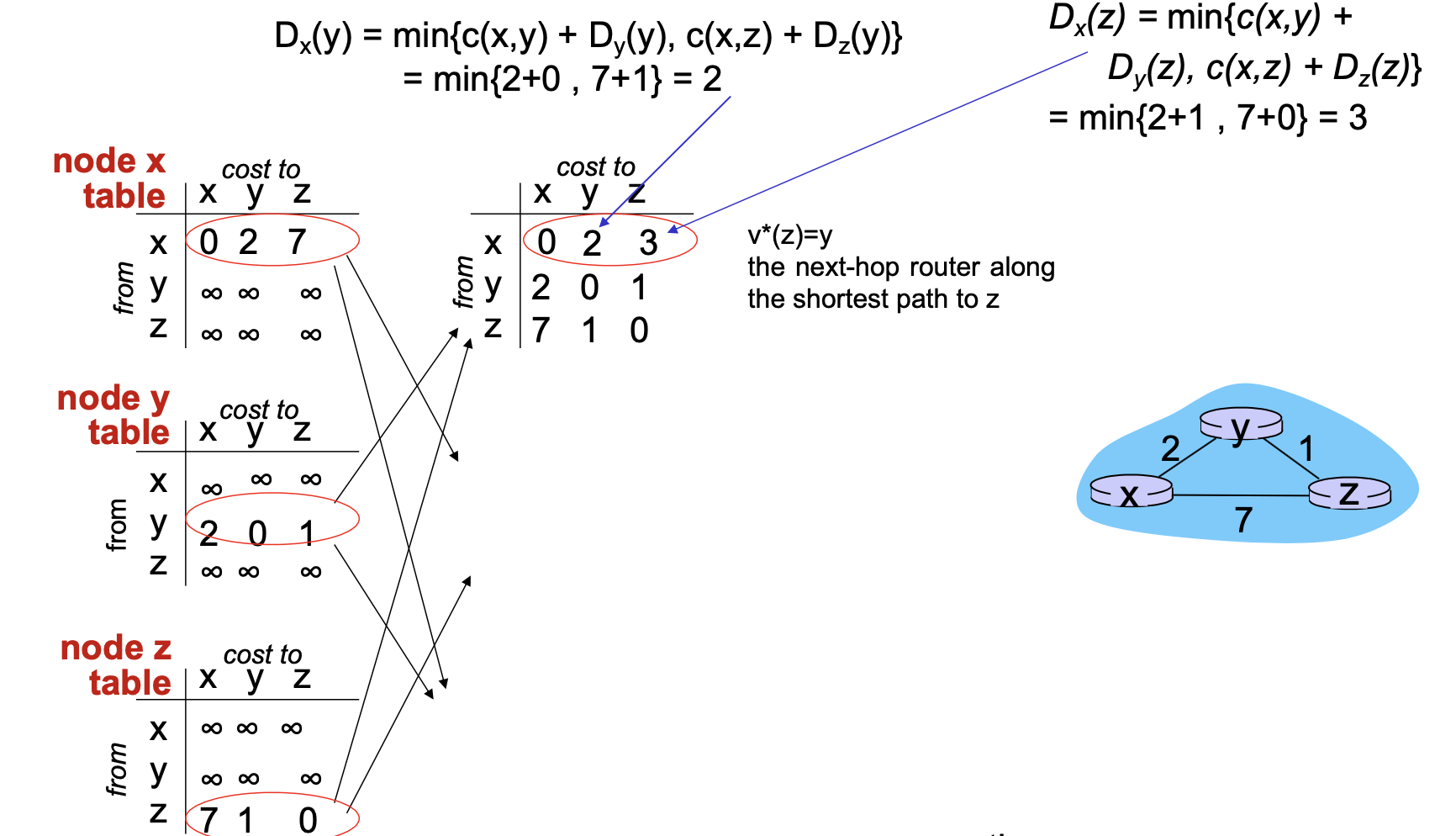
위의 그림은 Distance Vector 알고리즘을 좀 이해하기 쉽게 하기 위한 굉장히 간단한 토폴로지 인데요.
지금 x y g 3개의 노트로 구성돼 있고, 링크가 연결돼 있죠 각각의 링크에는 다음과 같이 link cost가 주어져 있습니다.
이런 상황에서 node x 입장에서 한번 테이블을 한번 생각을 해보겠습니다.
그럼 node x 입장에서는 지금 x에서 x까지는 당연히 0이겠죠.
또한 자기를 기준으로 해서 다이렉트 링크 직접 연결되는 노드에 디스턴스 벡터는 직접 구할 수 있습니다.
때문에 x에서 x는 0이고 x에서 y는 여기 그림에서 같이 2가 되고 x에서 z는 7이 되는 거예요.
나머지는 정보가 없어요.
y에서 x로 가는 거 y에서 y로 가는 거 y에서 지로 가는 거 즉 자기를 기준으로 해서 cost만 알고 있고 다른 것들은 일단은 모르니까 무한대로 이렇게 세팅을 해놓습니다.
그리고 y 입장에서 테이블 보면은 y도 y에서 x로 가는 거는 2, 그리고 y에서 y로 가는 거는 자기 자신이니까 0 그리고 y에서 b로 가는 거는 1입니다.
노드 z 테이블도 똑같은 방식으로 z 입장에서는
x로 가는 거 y로 가는 거 알 수 있죠 그래서 7 1 0으로 세팅이 돼 있습니다.
처음에 초기화된 테이블이 이렇게 갖고 있는 겁니다.
그 다음에 디스턴스 벡터 알고리즘은 자기가 가지고 있는 디스턴스 벡터를 교환합니다.
교환하면서 이제 내가 갖고 있는 정보보다 더 좋은 정보가 들어오면은 벨만 포드 이큐에이션을 통해서 업데이트 합니다.
z, y 테이블을 x가 받았다고 한번 가정을 해봅시다.

자기가 안 갖고 있어서 무한대로 표시했던 부분은 별만 포드 계산할 필요가 없습니다.
벨만포드 이큐에이션은 자기가 갖고 있는 정보보다 더 좋은 정보가 들어왔을 때 업데이트하는 겁니다.
이제 업데이트를 할지 안 할지 판단해야 될 부분은 이 첫 번째 줄이 됩니다. 여기서는 첫 번째 줄은 0, 2, 7로 값을 갖고 있었기 때문입니다.
그러면은 x 입장 x에서 y를 통해서 y로 갈 수가 있겠죠.
그러니까 x에서 y로 가고 y에서 y로 가는 경우는 지금 x에서 y로 가는 비용은 2이고, y에서 y이는 0이니까 2 더하기 0이니까 2가 돼요.
그다음에 이제 새로운 경로가 있는지 여기서 알 수가 있어요.
뭐냐면은 x 입장에서 y로 갈 때 x에서 y로 다이렉트로 갈 수도 있지만 이 z를 통해서 갈 수도 있다는 겁니다.
근데 z를 통해서 가는 거는 일단 초기 한테서 몰랐지만, 근데 지금 노드 z로부터 정보를 받으니까 계산할 수 있게 됐어요.
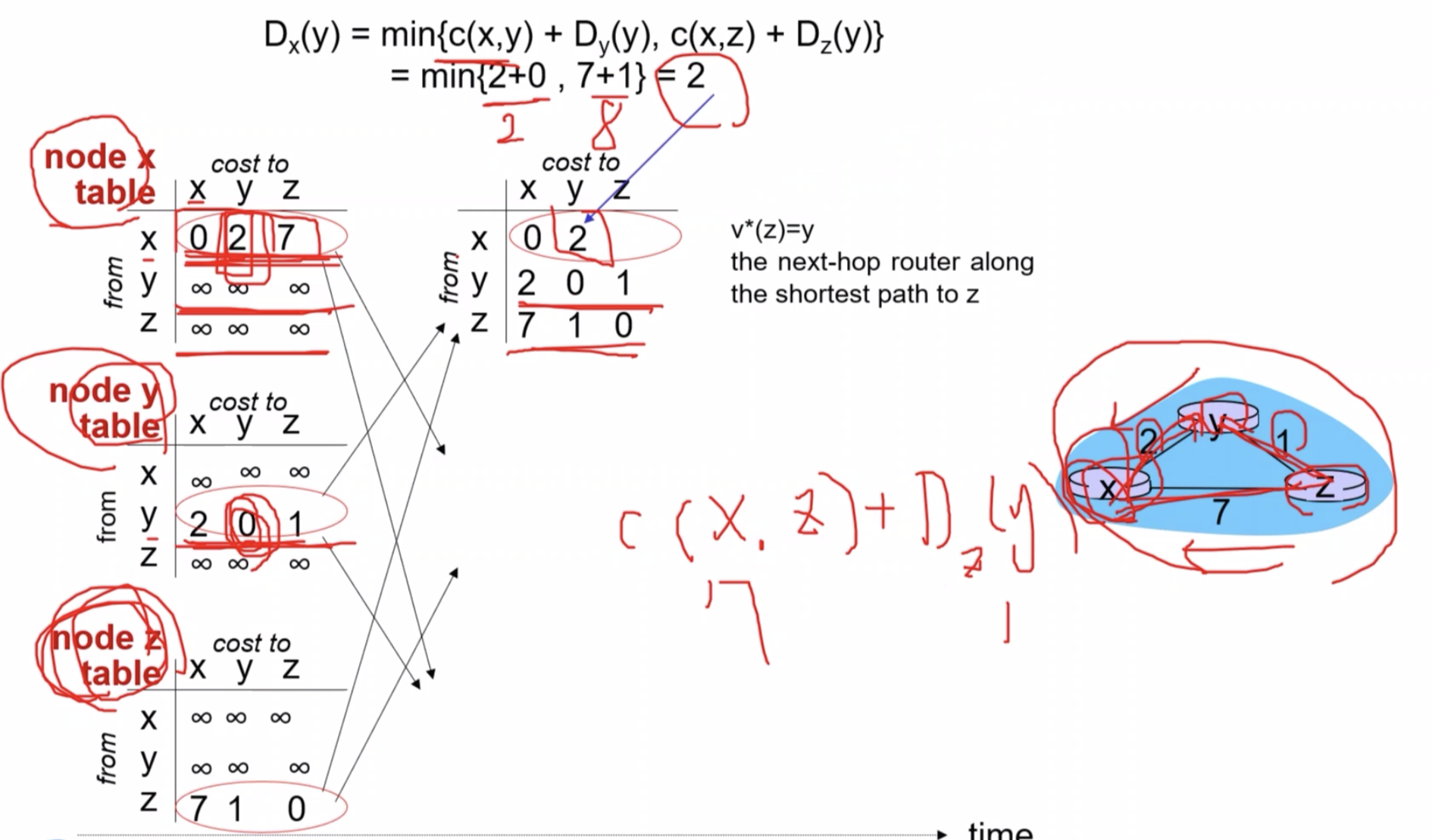
c(x, z) = 7
D(y) = 1 //z에서 y로 가는 비용
두 개 더 하면 8입니다.
8 그러면 여기서 min 값은 2하고 8 중에 2입니다.
그 말은 뭐냐면은 내가 가지고 있던 원래 값이 여전히 유효하다라는 거죠.
더 좋은 경로가 나타나지 않았다는 거니까 얘는 그대로 2라고 쓰면 돼요.
그러면은 x에서 z로 가는 거 한번 생각해 봅시다 x에서 z로 가는 거는 일단은 다이렉트로 가는 것밖에 몰랐습니다.
x에서 z로가 7이었죠. 근데 혹시나 테이블을 받음으로 인해서 내가 새로운 정보를 알게 됐는지 보자는 겁니다.
그래서 여기 식을 보면은요 먼저 z x y 즉 x에서 y로 가서 y에서 z로 가는 거예요.
그럼 x에서 y로 가는 거는 2 그리고 y에서 z로 가는 거는 1 이거는 어디서 알았냐면, 노드 y 테이블에서 알아온 것 입니다.
그래서 이거는 3입니다. 즉 뭐냐면은 x에서 z로 가고 z에서 z로 가는 거 에서 z로 가는 건 당연히 0 입니다.
그러면 7 더하기 0 이게 원래 가지고 있던 값입니다.
더 작은 값 찾았으니까 다음 같이 3으로 업데이트 해주는 겁니다.
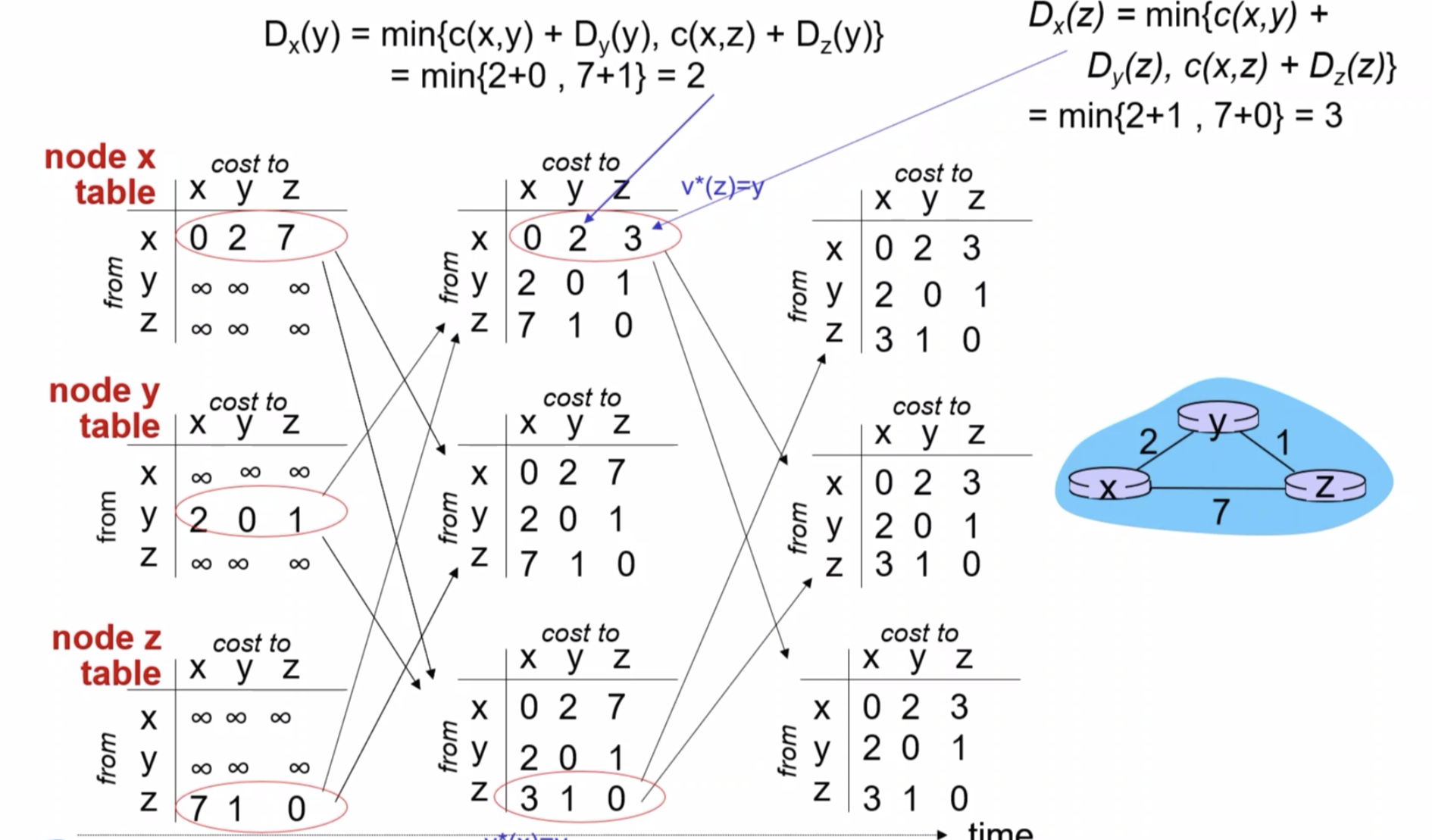
그래서 다음과 같이 업데이트하는 거 이 과정을 그냥 계속 반복하는 거예요.
이런 식으로 업데이트가 되면 또 업데이트된 정보를 또 다른 데 전파를 해야 돼요. 그러면은 또 이 업데이트된 전파를 또 다른 노드는 받을 겁니다.
그럼 받으면 지금 했던 것처럼 다시 계산을 해서 혹시나 더 짧은 경로가 발견됐는지 발견되면 업데이트해주고 발견 안 되면 원래 그거 킵해주고 그런 다음에 매 순간 자기가 가지고 있는 정보 있을 겁니다. 그걸 기준으로 라우팅을 하는 겁니다.
하지만, 디스턴스 벡터 알고리즘은 라우팅하는 시점에서 이게 최적의 경로를 보장하는 것은 아닙니다. 그냥 매 순간 그냥 내가 가지고 있는 최선의 정보로 라우팅을 하는 거예요.
하지만 계속 정보를 교환하고 교환하고 교환하다 보면은 롱텀으로 봤을 때는 이게 최적의 경로로 수렴할 수 있다라는 전제로 이 알고리즘을 쓰는 것 입니다.
그래서 다음과 같은 방식으로 이제 디스턴스 벡터 알고리즘이 동작을 하고요 디스턴스 벡터 알고리즘은 일단 다른 노드로부터 디스턴스 벡터 테이블을 받으면은 이렇게 재계산을 해서 업데이트 할 건 업데이트 합니다.
또한 자기의 이웃이랑 연결되는 노드에 링크 비용을 알고 있게 됩니다. 근데 이 링크 비용이 바뀔 수도 있겠죠.
링크 비용이라는 거는 이제 사업자가 어떻게 세팅하느냐에 따라 다른데 일반적으로는 이 연결 상태&연결 속도를 일반적으로 많이 사용을 합니다.
1-3. DV의 장점과 단점(인피니티 플라블럼)
그러면은 내 옆에 노드로 갈 때 링크가 지금 갑자기 느려졌어요.
그러면 당연히 이 링크 코스트가 바뀌겠죠. 비용을 더 늘리겠죠.
아니면은 지금 이 링크가 굉장히 지금 널널해졌다면, 링크 코스트가 좀 줄어들겠죠.
그래서 이렇게 내 링크 코스트가 바뀌게 되면은 그러면은 노드는 이 로컬 링크 코스트의 변화를 감지합니다.
디스턴스 벡터를 재계산하게 됩니다. 디스턴스 벡터를 계산했는데 만약에 값이 안 바뀌었다 그러면은 굳이 주변 노드들한테 알려줄 필요는 없습니다. 만약에 값의 변화가 있으면은 이웃들한테 이제 알려주게 되는 겁니다.
그래서 일반적으로 디스턴스 벡터 알고리즘을 이제 적용하게 되면은 이렇게 링크 코스트가 좋은 방향으로 바뀔 때가 있거든요.
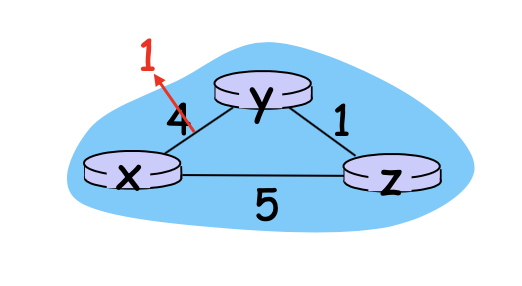
x에서 y로 갈 때 비용이 4였는데 1로 줄었습니다. 그 말은 링크가 더 빨라졌다는 겁니다.
만약에 속도라고 생각했으면은 더 빨라집니다. 그죠 근데 이 디스턴스벡터 알고리즘을 실제로 돌려보면은 이렇게 이 링크 코스트가 좋은 방향으로 바뀌었을 때는 굉장히 빠르게 다른 노드들한테 전파가 돼서 빨리 수령을 한다고 합니다.
이거를 이거는 사실 지금 했던 과정을 똑같이 해보면은 쉽게 알 수가 있거든요.
그래서 지금 업데이트하고 업데이트하고 업데이트하고 업데이트 하다 보면은 이제 노드들의 디스턴스 벡터 테이블이 금방 몇 번 이제 주고받으면은 수렴이 돼요. 한 번 받은 다음에 수정되는 게 아니라 주고받고 계속해야 됩니다.
주거니 받거니 주거니 받거니 하면서 케이블이 더 이상 안 변하는 시점이 있겠죠. 그게 어떻게 보면 수령된 시점입니다.
그 수령된 시점까지 빠르게 도달한다는 거예요.
디스턴스 벡터 알고리즘의 장점은 좋은 뉴스는 되게 빨리 전파된다 빨리 전파돼서 상대방의 디스턴스 벡터 알고리즘을 빠르게 수렴시킨다라는 좋은 점을 가지고 있습니다.
근데 반대로 이 디스턴스 벡터 알고리즘을 갖고 있는 단점이 있어요.
뭐냐면은 이 링크 코스트가 오히려 커지는 거예요. 커지거나 심지어 링크가 끊어지면은 무한대로 바뀔 수가 있죠.
이런 안 좋은 정보는 디스턴스 벡터를 이제 교환을 시켜보면은 이 로드뷰의 디스턴스 벡터가 어느 정도 스테이블 하게 될 때까지 굉장히 많은 이트레이션을 돈다고 합니다.
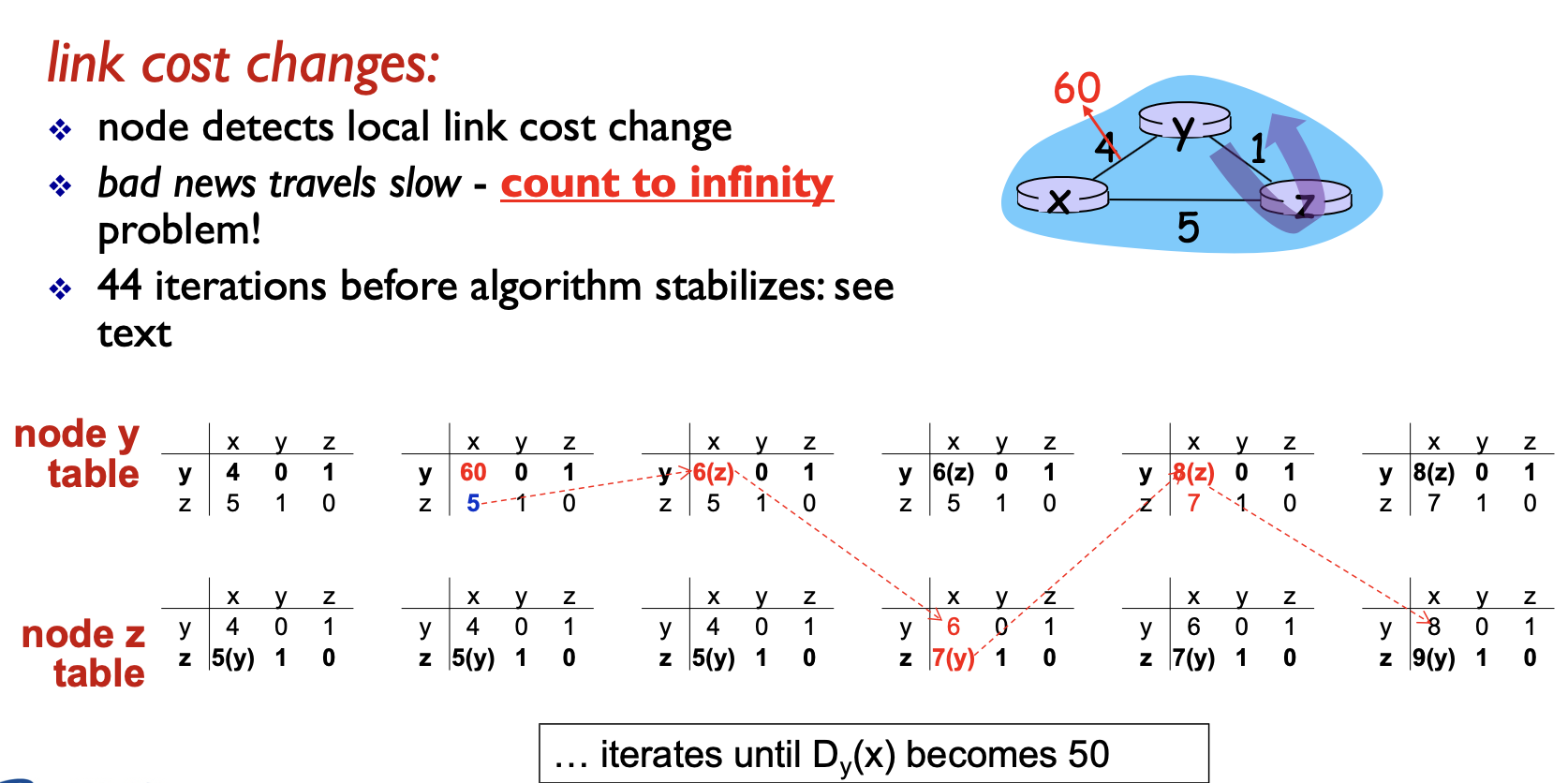
이런 간단한 토폴로지인데 이 링크를 4에서 60으로 바꿔봤어요.
60로 바꾼 다음에 각각의 노드들의 디스턴스 벡터가 더 이상 변하지 않고 어느 정도 스테이블 하게 될 때까지 약 44번의 이트레이션이 필요하다고 합니다. 44번을 그림에서 다 표현할 수가 없어요. 너무 많이 주고받고를 해야 되니까요.
그러니까 이 말은 뭐냐면은 링크 코스트가 좋은 방향으로 바뀔 때는 소식이 되게 빨리 전파돼서 금방 다른 노드들이 좋은 소식을 빠르게 수용해서 이 디스턴스 팩터가 수령하는데 안 좋은 소식은 계속 핑풍하면서 빠르게 수령하지 않고 굉장히 오랜 시간 동안 주거니 받거니 주거니 받거니 해서 수령까지 오래 걸린다는 의미입니다.
그래서 이거를 좀 어려운 말로는 카운트 인피니티 프라블럼이라고 합니다.
1-4. link state VS distance vector
디스턴스 벡터 알고리즘에서 그래서 우리가 지난번에 배웠던 이제 링크 스테이트 알고리즘은 이 수령과 관련해서는 이 디스턴스 벡터 알고리즘과 비교해서는 이슈가 없었어요. 왜냐하면 굉장히 빠르게 우리가 다익스트라 알고리즘을 돌릴 수가 있었잖아요. 근데 대신에 링크 스테이트 알고리즘은 일단은 전체 토폴로지를 갖고서 시작하죠. 그래서 전체 토폴질의 만들기까지의 비용이 많이 드는 알고리즘이고요 이 디스턴스 벡터의 장점은 전체 토폴리지에 모르는 상태에서 주변 노드들의 정보들만 취합해서 빠르게 의사결정을 할 수 있는 장점이 있는 알고리즘입니다. 하지만 이 옵티마로 수렴하기까지는 굉장히 많은 이트레이션이 필요하고 그리고 이 링크 스테이트가 고정이면 다행인데 계속 변하잖아요. 계속 변하는 링크 스테이트 상황에서 이걸 반영하기 위해서 혹시나 이제 링크 스테이트가 나빠지면은 굉장히 수렴이 이제 오래 걸리는 단점을 갖고 있는 알고리즘이기도 하다 이렇게 정리를 할 수 있을 것 같습니다.
그래서 지금 배운 거를 한번 여기서 정리를 한번 해봅시다.
그래서 링크 스테이트 알고리즘은 각각의 노드들이 다른 모든 노드들과 이제 이야기를 하는 구조입니다.
바로 플로딩이라는 절차를 통해서 내가 갖고 있는 정보들을 다른 모든 노드에게 전파시키는 과정을 거치게 됩니다. 그래서 각각의 이제 링크의 코스트들을 이제 말해주는 거죠. 그 다음에 그렇게 해서 전체 토폴로지를 만든 다음에 우리가 배웠던 다익스트라 알고리즘을 각각의 노드들이 직접 돌리게 되죠. 그래서 각각의 노드들은 다익스트라 알고리즘을 통해서 모든 데스티네이션에 대해서 최적의 아웃풋 링크를 도출하게 됩니다. 그래서 나중에는 ip 주소만 보고서 얘는 몇 번 링크로 보내는 게 제일 좋다라는 거 바로 알 수 있죠.
디스턴스 벡터 알고리즘도 똑같이 이제 모든 데스트네이션에 대해서 이제 아웃풋 링크를 결정하는 건데 이제 방법이 좀 다르죠 각각의 노드들이 자신과 직접 연결된 이웃과만 소통을 합니다. 그래서 플로팅 모든 노드에 전파시키는 게 아니라 자기 노드한 자기 이웃 노드한테만 전파를 시킵니다. 그리고 이웃 노드는 자기 이웃 노드한테 받은 정보를 가지고서 디스턴스 벡터 매번 업데이트를 합니다. 그리고 그 업데이트한 결과를 가지고 라우팅을 매 순간 수행을 합니다. 업데이트할 때 이제 사용하는 이큐에이션은 우리가 벨만 포드 이큐에이션이다라고 이야기를 했었습니다.
1-5. message complexity

각각의 알고리즘에 우리가 콤플렉스티를 한번 생각해볼게요. 먼저 메시지 콤플렉스틱 관점에서 보면은요 링크 스테이트 알고리즘은 우리가 로드가 n개 있고 링크가 e게 있다고 하면은 모든 로드에다가 다 전파해야 되잖아요. n 곱하기 e개 어떻게 보면 메시지가 발생한다라고 볼 수가 있습니다.
그래서 우리가 이 콤플렉스티라는 거는 시간 관점에서 콤플렉스티를 볼 수도 있지만 이렇게 시그널링 관점에서 콤플렉스티도 보기도 하거든요. 왜냐하면 이 시그널링이 결국 오버헤드니까 이 오버헤드가 도대체 얼마큼 발생하느냐를 분석하는 거예요.
그래서 링크 스테이트는 n e만큼 메시지 콤플렉시티가 발생하고요
디스턴스 벡터는 만약에 사실 이거는 일반화하기는 어렵지만 만약에 내 주변 이웃이 대략적으로 k 개씩 있다고 가정을 하면은 이 k는 당연히 e보다는 훨씬 작겠죠. 그렇기 때문에 n 곱하기 k만큼의 메시지 익스체인지가 발생한다고 합니다.
그래서 이 결과만 봤을 때는 링크 스테이트 알고리즘이 디스턴스 벡터보다 훨씬 더 좋다
그러니까 링크 스테이트가 디스턴스 벡터보다 메시지가 훨씬 더 많이 발생하니까 디스턴스 벡터가 더 좋다라고 말할 수가 있죠.
메시지 콤플렉스의 관점에서는 하지만 컨벌전스 관점에서 생각을 해보면요.
다음과 같이 이제 빅오 NE만큼 메시지가 전파가 돼서 전체 토폴로지를 만든 다음에 아이스 알고리즘은 대략적으로 n 제곱 콤플렉스를 갖고 있다라고 지난번에 이야기를 했죠. 그리고 이거를 n 로그 n으로 줄인 알고리즘도 있다고 했습니다. 그래서 대략적으로 이 정도 익스포네셜 컴플렉시를 통해서 우리가 링크 스테이트 알고리즘을 최적으로 수렴시킬 수가 있습니다. 근데 디스턴스 벡터는 사실상 옵티말로 컨버전스 할 때 어느 정도 이트레이션이 돌지 워널리티크하게 분석할 수가 없어요. 그러니까 약간 케바케인 거죠.
실제로 굉장히 많은 인터레이션에 수반하기 때문에 사실상 굉장히 느리게 컨버전스 한다라고 볼 수가 있습니다.
그래서 옵티말로 수렴시키는 관점에서는 이 링크 스테이트가 훨씬 더 이점이 있다라고 볼 수가 있겠습니다.
그래서 우리가 알고리즘을 이제 설계를 할 때 각각의 알고리즘이 사실 똑같은 목적을 통해서 만들어졌지만 이렇게 장단점이 서로 다른 경우가 되게 많거든요.
그러면은 우리가 이 이 알고리즘을 적용하는 환경 환경과 목적에 따라서 어떨 때는 링크 스테이트가 유리할 수도 있고 어떨 때는 디스턴스 벡터가 유리할 수도 있는 상황이 생깁니다.
2. routing scalable
대표적인 알고리즘 두 가지를 배웠습니다. 그럼 이게 실제로 어떻게 사용이 되고 있는지를 우리가 여기서 배워볼 예정입니다.
우리가 이 라우팅을 스카우트 확장성이 있게 만든다는 거거든요. 그래서 우리가 배웠던 이제 링크 스테이트든지 디스턴스 벡터든지 우리가 전 세계를 하나의 라우팅 도메인으로 묶으면은 적용할 수가 없어요.
링크 스테이트 같은 경우는 우리가 전 세계의 라우팅 토플로지를 실시간으로 전체 전 세계의 라우팅 토프로지를 얻는 게 불가능하겠죠.
너무 비용도 많이 들고요 그리고 그러다 보니까 거의 사실상 수렴은 불가능하겠죠.
그렇기 때문에 우리가 어느 라우팅 알고리즘을 쓰더라도 이 전 세계를 하나의 라우팅 도메인으로 묶는 거는 불가능하다 그렇기 때문에 한마디로 스칼러블 하지 않다. 확장성이 없다라는 거예요. 그래서 우리가 지난 시간에 이제 배웠던 거는 어떻게 보면 굉장히 아이디어라이제이션 굉장히 이상적인 상황에서 우리가 라우팅 알고리즘이 어떻게 동작하는지를 배웠던 것이지 실제 환경에서는 이 네트워크를 이렇게 플랫하다고 가정하지 않습니다.
왜냐면은 실제 전 세계에는 600밀리언 개의 데스테이션이 있기 때문에 이 모든 데스티네이션을 하나의 라우팅 도면으로 묶는 것도 불가능하고 또한 그 모든 데스트네이션에 대한 라우팅 테이블을 갖는 것도 불가능해요.
그러면 라우팅 테이블이 너무 커지기 때문에 이 라우팅이 많이 걸리겠죠. 우리가 모든 도메인을 다 필터링해야 되니까 그렇기 때문에 우리가 이 네트워크를 이제는 isp 단위로 쪼개서 각각의 이제 isp가 자신의 라우팅 도메인을 관리하도록 합니다.
그래서 이렇게 라우터들이 이제 하나의 region으로 묶여서 관리가 되는데요.
이거를 우리가 Autonomous Systems (AS)이라고 합니다. 어터너머스 시스템 혹은 도메인이라고 부릅니다.
2-1. Autonomous Systems (AS) : inter-AS / intra-AS
그래서 일반적으로 Autonomous Systems (AS)은 이제 라우팅이 적용되는 범위라고 생각하면 돼요. 라우팅 알고리즘이 적용되는 범위인데 근데 이 어터 시스템은 기본적으로 이 인터넷 서비스 프로바이더가 인터넷 서비스 프로바이더 별로 나눠진다고 보면 되겠어요.
예를 들어서 kt가 관리하는 아니면은 lg가 관리하는 Autonomous Systems (AS) 내에서 이제 라우팅이 일어나는 거예요. 그거를 우리가 뭐라고 부르냐면은 intra-AS 라우팅이라고 합니다.
즉 Autonomous Systems (AS) 안에 하나의 ISP가 직접 컨트롤할 수 있는 라우팅 도메인 있죠 거기서 일어나는 라우팅을 인프라를Autonomous Systems (AS)라고 해요.
근데 만약에 이 Autonomous Systems (AS)끼리 연결이 안 되면 어떻게 되죠.
as끼리 연결이 안 되면은 전 세계가 인터넷으로 연결될 수 있나요. 고립되겠죠.
그러면 as 안에서만 어떻게 보면 네트워킹이 되는 거지 전 세계가 연결되는 건 아니잖아요.
그래서 우리가 지금 살고 있는 세상은 전 세계 모두가 라우팅도 중요하지만 as끼리 연결시키는 라우팅도 필요합니다. 그거를 우리는 inter-AS 라우팅이라고 합니다.
즉, as 도메인 내에서 라우팅을 우리가 인트라 as 라우팅이라고 하고 그리고 as 간의 라우팅을 인터 as 라우팅이라고 합니다.
inter-as 라우팅은 호스트나 라우터 간의 라우팅인데 어떤 호스트와 라우터냐면은 바로 세 as 안에 있는 동일한 as 안에 있는 호스트와 라우터 간의 라우팅을 우리가 intra-as 라우팅이라고 합니다.
그렇기 때문에 이 as 안에 있는 모든 라우터는 당연히 동일한 라우팅 프로토콜을 사용해야 됩니다 라우팅 프로토콜이 다르면은 서로 호환이 안 되겠죠. 이 도메인에는 같은 라우팅 알고리즘 즉 같은 라우팅 프로토콜을 사용하는 방식으로 묶여야 됩니다. 그렇기 때문에 만약에 이 라우터들이 서로 다른 as에 있다라고 하면은 다른 인트라 as 라우팅을 프로토콜을 사용할 수도 있겠죠. 하지만 같은 곳에 있는 라우터들은 당연히 동일한 라우팅 프로토콜을 적용해야 됩니다.
이 as 안에 있는 라우터들 중에서도 인터 as 즉 다른 as에 있는 라우터랑 연결되는 애가 있거든요.
연결되는 애 즉 경계에 있는 라우터를 우리가 게이트웨이 라우터라고 합니다.
2-2. 게이트웨어 라우터
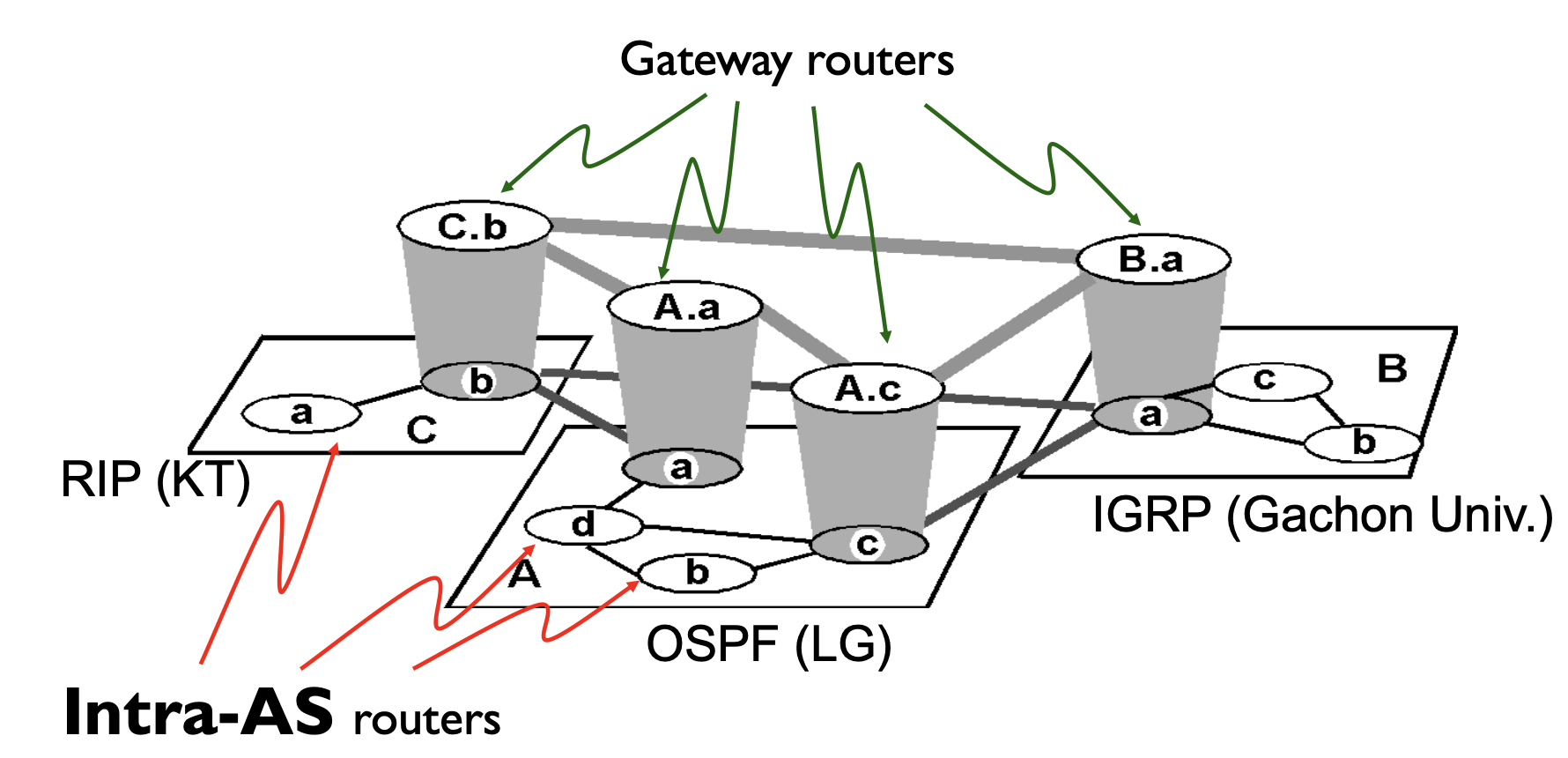
그래서 게이트웨이 라우터는 뭐냐면은 이 as에 이제 바깥 끝자락에 있어가지고 이 다른 as 라우터랑 연결되는 라우터를 말합니다.
어떻게 보면은 우리나라가 이제 외국으로 치면은 국경 국경이라고 생각하면 돼요 국경에 있는 보더 라인에 있는 그 우리가 이제 다른 나라로 가면은 어떻게 보면은 이제 공항 공항을 통해서 이제 다른 나라에 들어가잖아요. 그런 역할을 하는 게 이제 게이트웨이 라우터가 되는 겁니다.
그리고 인터 as 라우팅은 이제 as 간의 라우팅을 이제 말하는 거고요 그리고 이때 게이트웨이 라우터가 바로 인터 as 라우팅을 수행하게 됩니다.
as 그러고 as는 일반적으로 인터넷 서비스 프로바이더 단위로 나뉜다고 했죠. 그래서 여기서 예시로 든 거는 여기는 lg가 lg 유플러스가 관리하는 as구나 그냥 예시에요. 여기는 kt가 관리하는 as나 이렇게 여기는 가천대에서 관리하는 as구나 이렇게 as를 나눌 수가 있는 거예요. 그럼 이렇게 as가 나눴으면은 이 안에서 이제 라우팅이 일어나야 되잖아요. 여기서는 as 안에 라우터가 좀 적게 그려져 있긴 하지만 as 안에서도 라우터가 꽤 있거든요. as 안에서도 수십 개의 라우터가 존재할 수도 있어요. 그러면은 그 안에서 라우팅이 일어나야 되겠죠. 그거를 인트라 에이에스 라우터라고 하는 겁니다.
문제는 여기 안에서만 라우팅이 일어나면은 바깥으로 못 나가죠. 바깥으로 나가려면 반드시 접점을 통해서 나가야 되잖아요. 이 접점을 통해서 나가는 라우팅을 우리가 뭐라고 하냐면은 인터 as 라우팅이라고 합니다.
인터 as 라우팅을 담당하는 애들은 바로 이 접점에 있는 지금 회색으로 표시된 애들이거든요. 이 회색으로 표시된 애들을 우리가 게이트웨이 라우터라고 합니다.
인트라 as 라우팅 가장 흔한 라우팅 프로토콜이고요. 사용하는 프로토콜은 여러 가지 있는데 대표적인 게 이 세 가지가 되겠습니다.
그래서 rip 라우팅 인포메이션 프로토콜이랑 그리고 ospf 오픈 숄티 퍼스트 프로토콜이랑 그리고 igrp 인테리얼 게이트웨이 라우팅 프로토콜 이게 세 가지가 대표적으로 있습니다.
게이트웨이 라우터는 각각의 as 마다 하나씩 있는 거냐 이렇게 질문이 있는데요.
하나만 있는 건 아니에요. 여기 그림에서 여기 예시 그림만 봐도 지금 여기 두 개가 있죠.
이렇게 이쪽으로 나가는 거 하나 이쪽으로 나가는 거 하나 이렇게 두 개가 있잖아요.
그래서 이거는 제약이 없어요. 네 내가 이제 인터 as랑 몇 개의 인터 에이스랑 접하고 있느냐에 따라서 게이트웨이 라우터가 달라질 수가 있어요.
그래서 이렇게 이제 세 가지가 있는데 여기서 가장 이제 대표적인 ospf를 우리가 기준으로 살펴볼게요 ospf가 이제 표준화된 표준화된 가장 이제 보면적으로 사용되는 프로토콜이고요 그다음에 igrp 같은 경우는 시스코에서 자체적으로 만든 라우팅 프로토콜입니다.
그래서 그런데 이 igrp도 이 ospf 기반으로 만들면서 조금 더 이제 기능을 애동을 해서 이제 어떤 기능을 애도했는지 다 자기들의 제 특허 특허를 이제 확보를 하고 있겠죠.
2-3. OSPF
그래서 우리가 가장 기준이 되는 ospf 기준으로 이제 설명을 하겠습니다.
그래서 오픈 쇼티스 패스 퍼스트라는 ospf라는 프로토콜은 일단 오픈이라는 말은 이제 국제 표준으로 돼서 누구나 다 이 ospf가 어떻게 설계됐는지를 국제 표준 문서를 보면 알 수 있다는 거예요.
이거는 이제 특허 치매 없이 우리가 ospf을 구현해서 팔 수 있는 거예요. 구현해서 팔 수 있으면 거 네 이제 시스코가 왜 ospf를 그대로 안 쓰냐 시스코는 자기네 네가 이미 라우터 시장을 꽉 잡고 있잖아요. 그러니까 이 ospf를 그대로 따라서 만들면은 어떻게 보면은 자신의 경쟁력이 엄청 크진 않겠죠. 왜냐하면 이건 너도 나도 따라서 만들 수 있는 거니까 그러니까 ospf를 기반으로 하되 자기네들이 조금 더 기능이 좋아지도록 이제 비밀 기능 같은 것도 다 탑제해가지고 자기네 어떻게 보면은 내부 프로토콜을 만들어서 쓰는 거예요. 그렇게 해서 시장의 진입 장벽을 만들면서 계속계속 자기가 가지고 있는 시장을 좀 유지하려는 이제 목적인 거죠. 여러 가지 분석들이 있지만 그래도 이 ospf를 기반으로 해서 이 시스코가 계속해서 기능을 애동을 하고 있다.
이 ospf는 이제 우리가 앞에서 배웠던 링크 스테이트 알고리즘을 이제 구현한 프로토콜이라고 보면 되겠습니다.
링크 스테이트 알고리즘 그렇기 때문에 링크 스테이트 인포메이션이랑 다익스트라 알고리즘을 활용하는 플로폴입니다.
링크 스테이트 인포메이션이랑 다익스트라 알고리즘 그래서 당연히 우리가 링크 스테이트 알고리즘에서 배웠던 것처럼 패켓 플로딩 과정이 필요하고요
그래서 토폴로지 맵을 만들어냅니다. 그렇기 때문에 이런 플로딩하는 과정이 필요하니까 이런 플로딩을 지원하는 프로토콜이 정의가 돼 있어야 되겠죠. 이런 것들이 이제 ospf에 정의가 돼 있는 거예요. 그리고 플로딩을 통해서 토폴즈 맵이 만들어지면은 이제 다익스트라 알고리즘을 적용해서 이제 포워딩 테이블을 도출합니다. 그래서 라우터는 이 ospf 링크 스테이트 애드벌타이즈먼트라는 과정을 통해서 모든 노드들이 as 안에 있는 모든 라우터들에게 플루드를 적용합니다.
그래서 만약에 링크 스테이트에 변화가 생겼다. 그러면은 다시 플로딩을 하는 거예요. 왜냐하면 토폴로지를 다시 업데이트하기 위해서 그래서 토플로지 계속 계속 최신 상태로 업데이트하기 위해서 링크 스트레이트에 변화가 생기면은 폴딩 전체한테 폴딩하는 작업을 진행하도록 이제 ospf가 지원을 하고요 그리고 만약에 변화가 없어요. 변화가 없으면은 변화가 없으면 플로딩을 안 할까요.
그 원칙적으로 변화가 있으면 가 업데이트를 해야 되는 거잖아요. 그럼 변화 없으면 플링 안 해도 될까요?
여기서는 변화가 없어도 최소 30분 이거는 이제 컨피그레이션 하기 나름이지만 대략적으로 30분마다 주기적으로 플로딩을 하게끔 설정이 돼 있어요.
왜 그러냐면은 만약에 일단 링크 스테이트 변화가 있을 때만 보낸다고 했잖아요. 근데 만약에 라우터가 고장이 났어 죽었어 죽을 수도 있죠.
죽으면은 보낼 수 있어요. 없어요. 변화가 있어도 못 보내죠 그러면 사실상 얘가 변화가 없어서 안 보내는 건지 아니면 얘가 죽어서 안 보내는 건지 구분할 방법이 있나요. 라우터가 만약에 죽었다. 뻗어버려 우리 컴퓨터도 갑자기 꽂을 수 있잖아요.
라우터도 어떻게 보면은 일종의 컴퓨터니까 아 아무리 안정적으로 설계를 해도 문제가 생길 수 있단 말이에요. 갑자기 뻗는다든지 아니면 전원 공급이 잘 안 돼가지고 죽을 수도 있고 그렇죠 근데 만약에 상대방은 ospf 메시지가 안 오니까 링크 스테이트가 안 바뀌고 잘 있나 보구나 이렇게만 판단할 수 있잖아요. 그런데 실제로 애가 죽은 거예요.그러면 문제가 생기겠죠. 라우팅 테이블 만들 때 죽은 애한테 계속 패키지 보낼 수도 있잖아 그래서 이렇게 주기적으로 보내는 이유는 내가 살아있다라는 것을 알리기 위한 용도로 사용이 됩니다. 그러니까 내가 링크 스크립트 변화가 없더라도 일정 30분 30분 1시간마다 보내는 거는 변화는 없지만 나는 지금 잘 살아있다라고 알려주는 용도는 되겠죠.
이렇게 주기적으로 안 오면은 그때부터는 이제 변화가 없다는 게 아니라 애가 죽었다라는 걸 의심할 수 있는 거예요. 왜냐하면 애가 살아 있으면은 주기적으로 리포트를 해줄 거니까 그래서 이건 비단 라우트뿐만 아니라 시스템 관련해서 등산 시스템에서도 굉장히 많이 사용하는 기법입니다. 이거를 우리가 조금 어려운 말로는 하트 빗 메시지라고 하거든요.
내가 우리가 사람이 사라지면 심장이 뛰잖아요. 그런 것처럼 여러 개 이제 분산된 분산 시스템에서 각각의 시스템들이 살아 있다라는 거 이제 심장 박동 하는 걸 알려주는 용도입니다.
그다음에 이제 이 ospf의 어드벤스별 특징으로는 이제 보안 기능도 있는데요. 모든 이제 ospf 메시지는 이제 인증을 요구를 합니다.
그래서 보안 측면에서도 굉장히 안정적으로 돌아가게 합니다. 왜냐하면은 만약에 이 ospf 메시지가 해킹이 돼가지고 해커들이 뭔가 ospf 메시지를 뭔가 변조한다거나 하게 되면은 라우팅 꼬이게 만들 수도 있겠죠. 어떻게 보면 이번에 kt 문제도 라우팅 테이블을 업데이트하다가 꼬여가지고 전체 라우팅이 꼬여버린 거거든요. 해커가 악의적으로 라우팅 테이블에 접근해서 라우팅 테이블을 이상하게 만들어버리는 거예요. 라우팅 엉망이 되게 그런 걸 막기 위해서 굉장히 보안적으로도 강화된 기능을 제공한다
2-4. 인트라 as 라우팅과 인터 as 라우팅이 어떻게 적용?
그래서 이번에는 이제 이 인트라 as 라우팅과 인터 as 라우팅이 어떻게 적용되는지를 우리가 살펴볼게요.
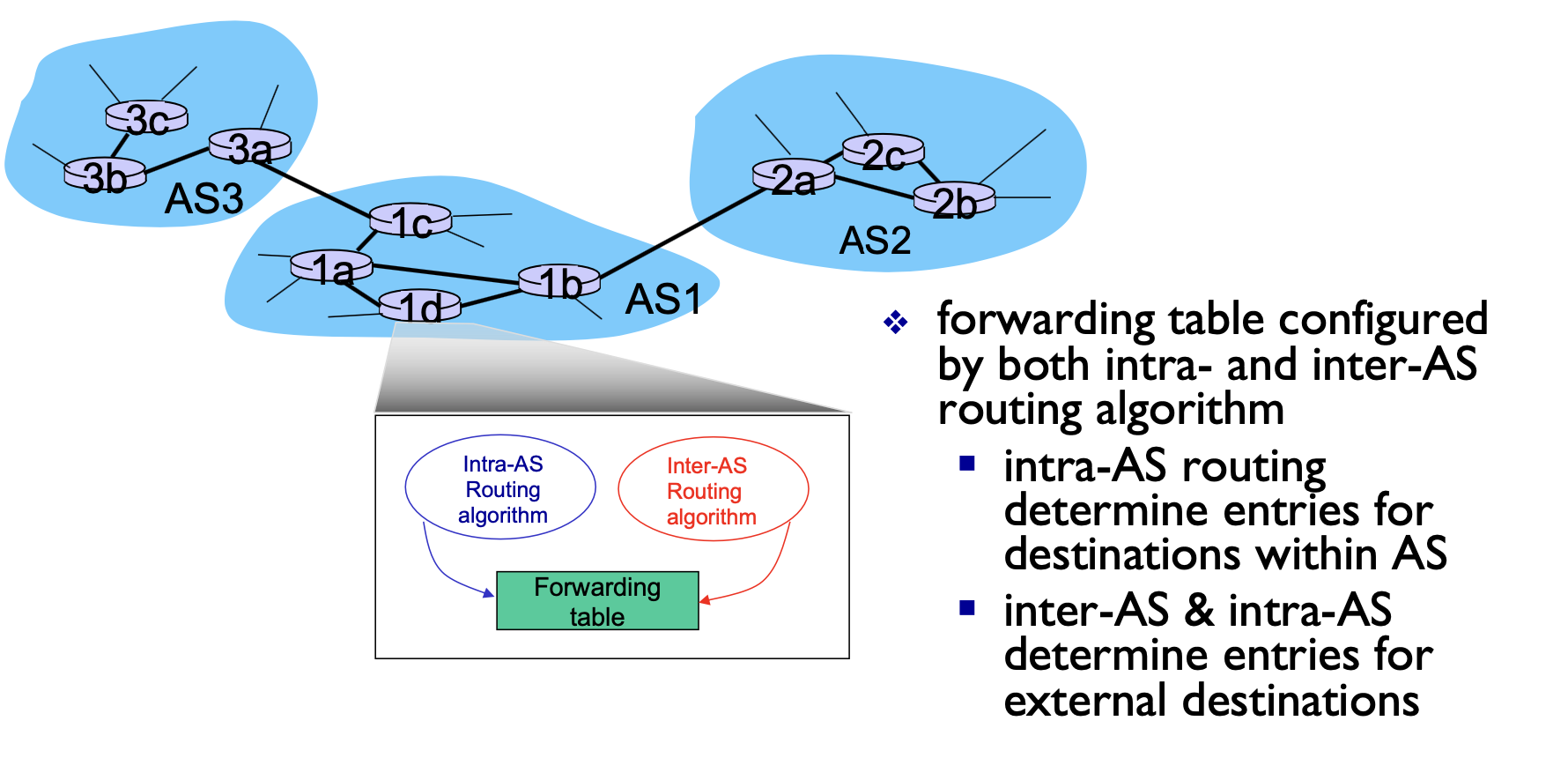
여기서 보면은요 인트라 as 라우팅 알고리즘과 인터 as 라우팅 알고리즘이 서로 협력해서 포워딩 테이블을 도출하는 걸로 나와 있어요.
그래서 fin 케이블은 이제 두 개의 라우팅 알고리즘에 의해서 적용되는데 먼저 인트라 as 라우팅은 as 내에 있는 모든 엔트리에 대해서 이제 최적의 경로를 도출하는 게 되고요 그리고 인터 as랑 인트라 as가 서로 협력해서 결정하는 거는 뭐냐면요.
만약에 목적지가 as 바깥에 있을 수도 있죠. 그럼 as 바깥에 있으면은 어디를 통해서 나가는지를 결정하는 게 인프라 as랑 인트라as가 서로 협력해서 결정하는 거라고 볼 수가 있습니다.
그러니까 여기서 중요한 거는 뭐냐면요. 이 인터 as가 하는 일은 내가 만약에 바깥으로 나가려고 하면은 어딜를 통해서 나가는지만 알면 되잖아요. 그러면 어디 통해서 나가면은 이제 그쪽에서 또 다시 또 as 라우팅이 돌겠죠. 인트라 as 라우팅이 그러니까 우리가 전체 경로를 알 필요가 없어요.
그러니까 예를 들어서 내가 내가 만약에 미국으로 가고 싶어요. 미국 가고 싶으면은 지금 단계에서 만약에 미국 뉴욕으로 가고 싶다.
그러면은 여기서 미국의 전체 테스트를 내가 다 결정할 필요는 없는 거예요. 뭐냐면은 일단은 미국으로 가려면은 우리나라에서 어디서 어떤 비행기를 타야 되는지만 사실 알아도 되죠. 그렇게 해서 그럼 인천공항 김포공항이 아니라 인천공항을 타서 미국 어디 비행기를 타야 된다라는 것만 알면은 일단 미국 어딘가 도착할 거잖아요. 그럼 그 안에서 다시 미국 안에서 또 라우팅 해도 되잖아요.
그러니까 결국에는 내가 바깥으로 나갈 때 어디를 통해서 나가는지만 알면은 그다음에는 이제 바깥으로 나가서 거기서 또 as 라우팅이 돌면 되는 거예요. 그래서 여기 인터 as랑 인프라 as는 이 외부 목적지를 통해서 외부 목적지로 갈 때 어느 게이트웨이를 통해서 나가야 되는지를 결정하는 역할을 합니다.
그것만 알면은 사실상 그 게이트웨이 통해서 나가면은 다시 또 여기서 as 라우팅이 도는 거예요.
인트라 as 라우팅 그래서 인터 as 라우팅의 이제 역할은 뭐냐면요.
지금 여기 그림에서 여기가 as 1이거든요. as1에 있는 라우터가 as 1 바깥에를 목적지로 하는 데이터그램을 받았다고 합시다 그러면은 라우터 입장에서는 이 패킷을 어떤 게이트웨이 라우터를 통해서 보내야 될지가 이제 고민인 거예요.
왜냐하면 게이트웨이가 두 개밖에 없죠. 지금 이 보드에 접하고 있는 애가 게이트웨이라고 했잖아요.
데스트네이션이 어느 쪽이냐에 따라서 얘를 통해서 보낼 건지 얘를 통해서 보낼 건지를 결정을 해야 됩니다.
그래서 as 1은 일단은 이 as2 내 게이트웨이가 접하고 있는 도메인이 as 2라는 거 알고 있어요.
그럼 이 as2를 통해서 어떤 목적지에 도달할 수 있는지를 먼저 배워야 됩니다.
그리고 이 as2를 통해서 어떤 베스트네이션에 접근할 수 있는지를 알았으면은 그것을 이 내부에 있는 라우터들한테 알려줘야 돼요. 그래서 뭐냐면은 라우터 1 b를 기준으로 생각해봅시다.
이 1b 입장에서는 나는 as2랑 연결이 돼 있어 근데 as2를 통해서 어떤 라우터에 접근할 수 있어라는 정보를 얘가 수집을 해야 되는 거예요.
1 b가 그럼 수집하고 끝이 아니라 수집한 정보를 이 as 안에 있는 모든 라우터들한테 알려줘야 돼요 그렇죠 그거 알려주면은 나중에 만약에 이 이 라우터에 가려고 해요. 이 라우터에 가면 이제 얘네들 알잖아요. 알았으니까 그러니까 이 익스터 라우터 얘를 통해서 가려면은 as2를 통해서 갈 수 있는데 그러면은 1b한테 보내줘야 되겠구나라는 거를 판단할 수 있다는 거예요.
그래서 이 이 게이트웨이 라우터의 이제 역할을 정리해보면은요.
뭐냐면은 익스터널 네스네이션 접근할 수 있는 접근 가능한 라우터들을 내가 수집을 하고 그 수집된 정보를 내부에 퍼뜨리는 역할 이 두 가지 역할을 수행해야 됩니다. 이게 인터 as 라우팅 프로토콜의 역할이에요.
2-5. BGP
그래서 인터 as 라우팅 프로토콜의 이제 표준화된 이름은 bgp라는 프로토콜이에요.
bgp 그래서 풀어서 보면은 보더 게이트웨이 프로토콜입니다. 보더 그 경계에 있는 게이트웨이 프로토콜이다.
이런 의미죠 그래서 이거는 이제 인터넷을 어떻게 보면은 붙여주는 역할을 해주는 프로토콜이 되겠고요.
bgp는 두 가지 방식으로 동작을 해요. 하나는 이 eBGP고요 하나는 iBGP거든요.
eBGP는 뭐냐면요. 주변에 나랑 접하고 있는 as로부터 reachability information을 수집하는 역할을 합니다.
eBGP프로토콜은 먼저 출입하는 역할을 한다고 했었잖아요. 그러니까 나랑 지금 접하고 있는 이웃 as로부터 어떤 익스터널 데이스테이션에 접근할 수 있는지를 표집하는 역할 그러니까 이런 거죠.
그건 수집하고 끝나는 게 아니라 수집한 다음에는 그 수집된 정보를 광고해야 되죠 광고해야 되지 사람들이 그걸 보고서 이제 여행 갈 때 참고할 거잖아요. 그런 것처럼 iBGP는 뭐냐면은 지금 수집한 이 reachability information을 이제 as 인터널 라우터들한테 뿌려주는 역할을 하는 게 이 iBGP 프로토콜입니다.
그래서 이때 이제 우리가 이제 만약에 복수에 이제 어떤 익스터널 라우터로 갈 때 가는 방식이 한 개만 있으면은 심플한데 여러 방식이 있을 수도 있잖아요. 그럼 여러 방식이 있을 때 어떤 걸 선택할 거냐는 따로 알고리즘 없어요. 이 인터네이스 라우팅 프로토콜은 폴리시 기반으로 동작을 합니다. 폴리시라는 거는 사업자가 컴플리케이션 하기 나름이에요. 룰에 의해서 결정됩니다.
그리고 심지어 내가 내가 이웃 as한테 나를 통해서 갈 수 있는 경로를 알려주기 싫을 수도 있죠. 그러면은 아무리 이 bgp가 나를 통해서 정보를 얻으려고 해도 정보 제공하는 거를 거부할 수도 있어요. 마치 우리가 다른 나라로 여행 갈 때 우리가 모든 나라 여행할 수 없는 거지 여행할 수 없죠. 어떤 나라에서 우리나라 막으면 못 가는 거잖아요. 이거는 알고리즘에 해서 결정되는 건가요 아니죠. 국가 간의 이해관계에 의해서 결정되는 거죠.
갑자기 어떤 나라에서 어떤 나라는 코로나 때문에 위험한 것 같으니까 우리가 안 받으려고 하면 안 받는 거잖아요. 그런 것처럼 인터 as 라우팅은 어떤 알고리즘에 의해서 결정된다기보다는 as를 관리하는 isp의 포스에서 실제로 결정이 되고 운영이 됩니다.
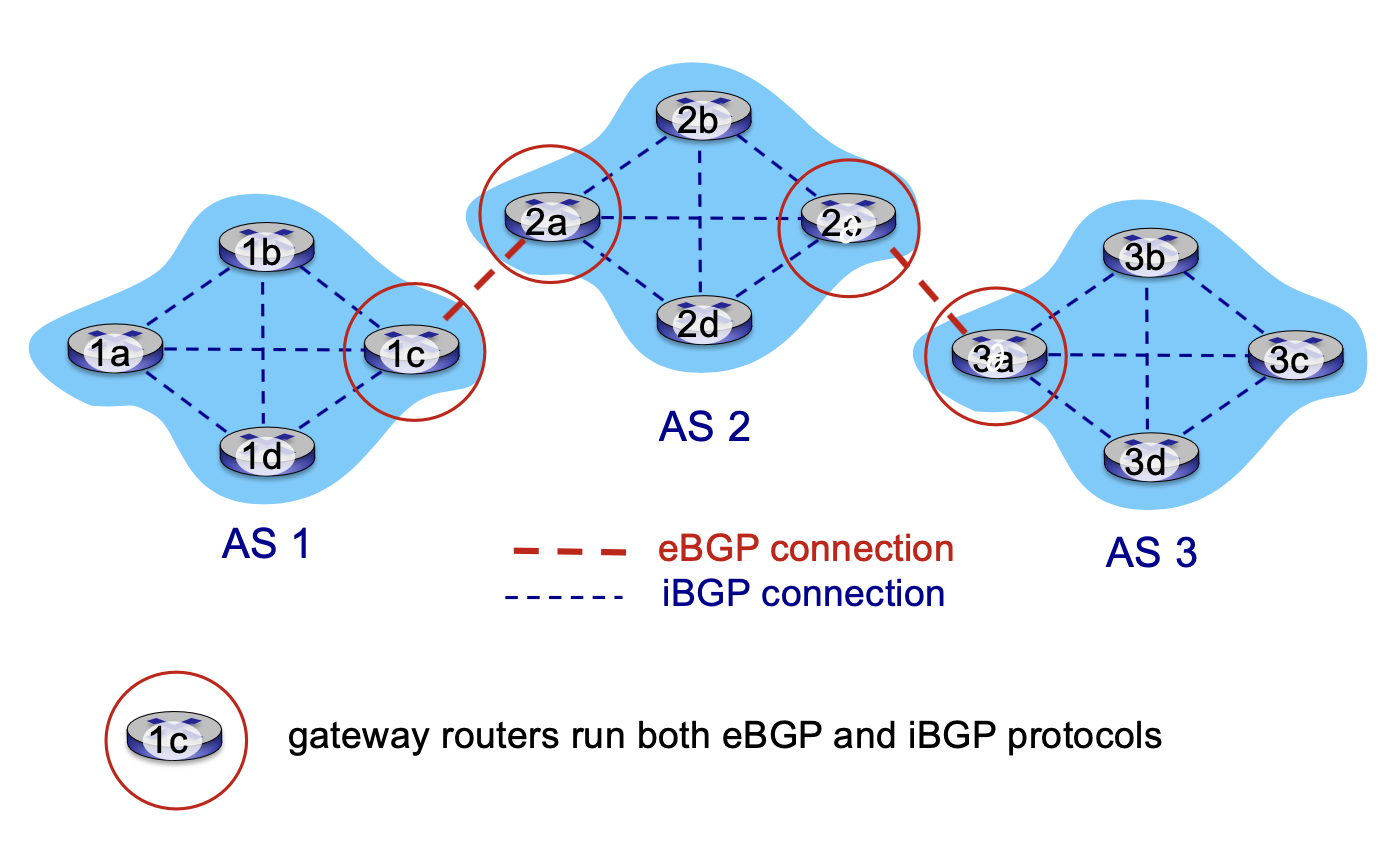
지금 그림은 앞에서 설명한 개념을 한번 그림으로 표현하고 있는 거거든요.
그래서 ebgp랑 ibgp가 어떻게 동작하는지 그림을 보면 쉽게 매핑할 수 있을 것 같습니다.
그래서 여기서 보면은요 지금 ebgp 부분 봅시다 ebgp 부분이 여기 빨간색으로 표시된 부분이에요.
이렇게 제가 지금 표시하고 있는 거 그러니까 뭐냐면은 이웃 Autonomous Systems로부터 이제 reachability information들을 수집해야 되잖아요. 그래서 이웃 정보를 이웃 게이트 웨이 라우터를 통해서 정보를 수집하는 과정을 수행하는 프로토콜이 ebgp입니다.
i bgp는 이 수집한 정보를 자기 내부에다가 퍼뜨리는 거라고 그랬죠 그러니까 여기 그림에서 이 파란색 점선 부분 있죠. 점선을 통해서 이제 정부가 전파가 되는 거예요. 그래서 두 개의 bgp 라우터가 이제 bgp 메시지를 이제 tcp 커넥션을 통해서 이제 교환을 하고요 그리고 이제 경로를 다른 목적지 네트워크 prefix에 전파를 해줍니다.
예를 들면은 이런 거예요. 그러니까 지금 이 as3가 이 서브넷 엑스가 as3에 연결이 돼가지고 as 소리를 통해서 서브는 x의 접근이 가능하다고 합시다 그러면은 이 as3에 있는 이 게이트웨이 라우터가 이거를 자기 주변 as에다 알려주는 거야 이거를 우리가 bgp 애드벌타이스먼트라고 합니다.
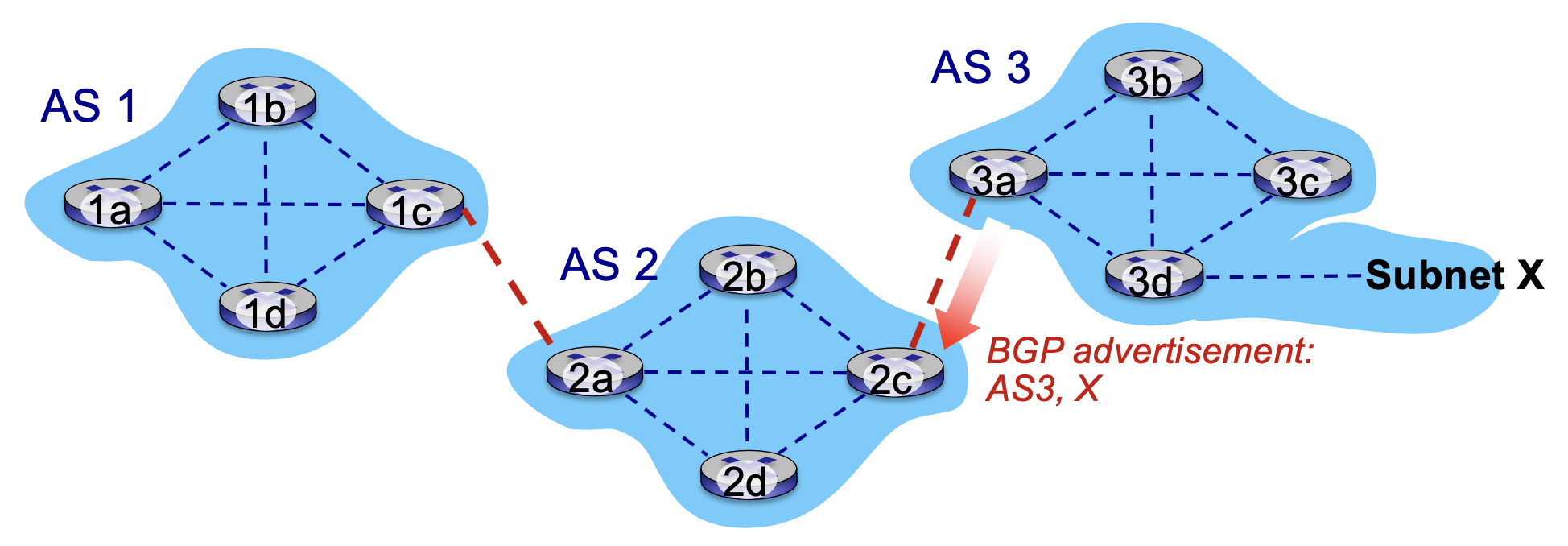
bgp 이제 광고죠. bgp 애드벌타이스먼트 그래서 예를 들면은 이러한 정보들이 이제 bgp 프로토콜에 당기는 거야 나는 이제 as3인데 나를 통해서 x에 도달할 수 있어라는 정보를 지금 이웃 as인 2c라는 게이트웨이 라우터한테 알려주는 거예요. 이 bgp를 통해서 그래서 게이트웨이 라우터 3a는 패스 as3를 통해서 x에 갈 수 있다는 것을 as2 게이트웨이에다가 광고한다 그 말은 뭐냐면은 as3가 as2한테 만약에 엑스로 가는 데이터 그램을 나한테 전달해주면은 내가 x까지 보내줄 수 있다라는 걸 어떻게 보면은 약속하는 거라고 볼 수 있겠죠.
만약에 내가 이 엑스에 가는 패킷을 포워딩 하기 싫다라고 하면은 광고를 안 하면 됩니다. 이렇게 애드벌타이즈 타입으로 할 건지 안 할 건지도 이제 policy 의해서 결정이 됩니다.(policy based routing)
그래서 다음과 같이 이제 라우트 광고를 이제 받게 되잖아요.
게이트웨이 라우터가 그러면은 이 이제 자기가 애드벌타이스먼트를 받았다고 해서 이거를 반드시 수용해서 내부로 전파하는 것은 아닙니다. 받고 이걸 그냥 무시할 수도 있죠. 무시하면은 이제 ibgp로 전파를 안 하면 돼요 근데 만약에 내가 이 경로를 accept하겠다라고 하면은 이제 내가 ibgp를 통해서 내부에다가 전파를 하면 되겠습니다. 그리고 as policy는 이제 이 패스를 다른 이웃한테 광고 할 건지 말 건지를 결정하는 것도 이제 포함을 하고 있습니다.
정리하자면 내가 전파된 정보를 수용할지 말지도 폴리스에서 결정할 수 있고 내가 전파를 할지 말지도 policy 의해서 결정할 수가 있습니다.
그래서 as2 라우터가 as2라우터 2c가 as3로부터 지금 나를 통해서 x에 갈 수 있다라는 거를 알려주고 있는 거예요.
이때 사용하는 프로토콜은 뭐다 ebgp 그렇죠 그리고 지금 as2의 2c는 지금 이 애드벌 타이스먼트를 이제 수용하기로 했어요.
수용하기로 했으니까 이제 내부에 전파를 합니다.
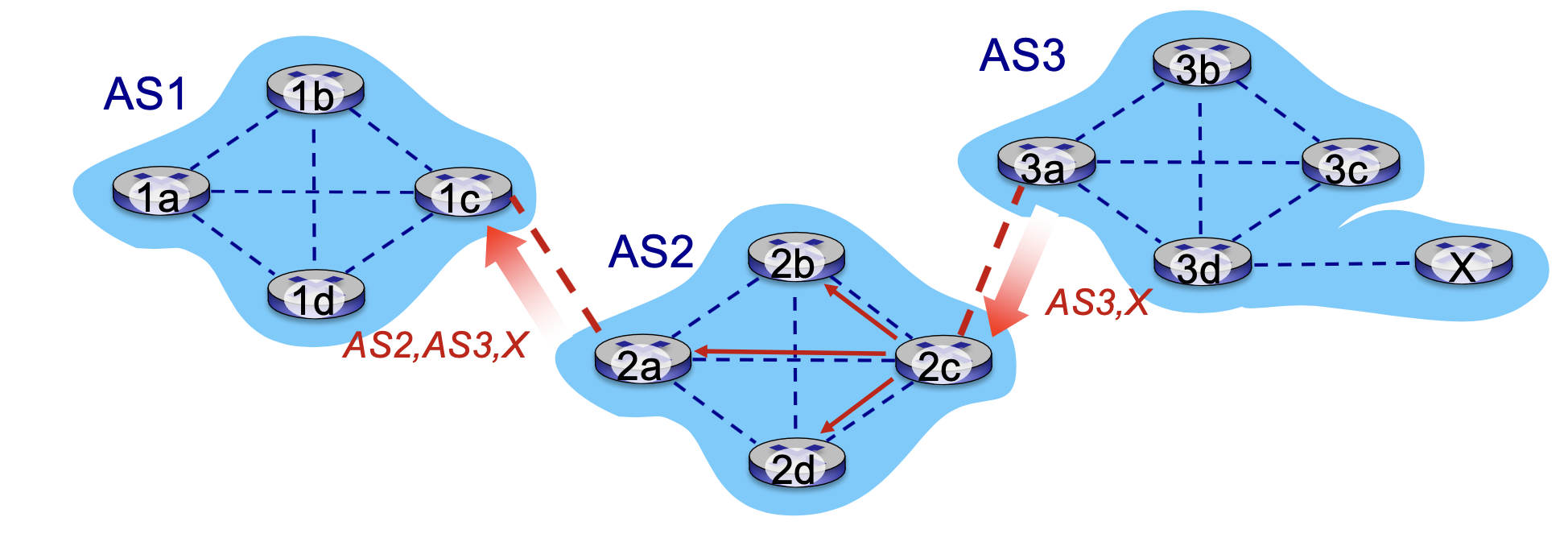
AS2라우터 2c는 전달받은 as3를 통해서 엑스에 갈 수 있다라는 패스를 억셉하고요 그리고 이거를 이제 프로파게이 시킵니다.
as 내에 있는 모든 라우터들에다가 전파를 시킨다 이때 사용하는 프로토콜은 뭐다 ibgp다 그쵸 그래서 이 bgp는 ebgp/ibgp 두 개로 나눠진다라는 거를 잘 기억을 해야 되겠어요.
그러면 여기서 이제 한 스텝 더 가봅시다. 2a도 게이트에 라우터죠. 지금 ibgp를 통해서 이 as3를 통해서 x에 갈 수 있다라는 거 배웠죠.
지금 as3를 통해서 x에 갈 수 있다는 거를 2c가 알게 됐고 2c가 내부에 있는 라우터들한테 다 알려줬잖아요. 얘도 이제 x라는 데스티네이션은 우리 옆에 있는 as3를 통해서 갈 수 있다라는 거를 2a도 배웠죠 그러면 얘도 누구한테 이 소식을 베이스 1에 있는 1c한테 알려줄 수 있겠죠.
그래서 여기 보면은 만약에 목적지가 x인 내가 있다면은 우리(as2)를 거쳐서 as3를 거쳐서 갈 수 있으니까 나한테 전달해 주면 돼라는 새로운 패스를 또 as1한테 알려줍니다.
이런 식으로 해서 이제 인터 as 라우팅을 통해서 정보들이 교환이 되는 겁니다.
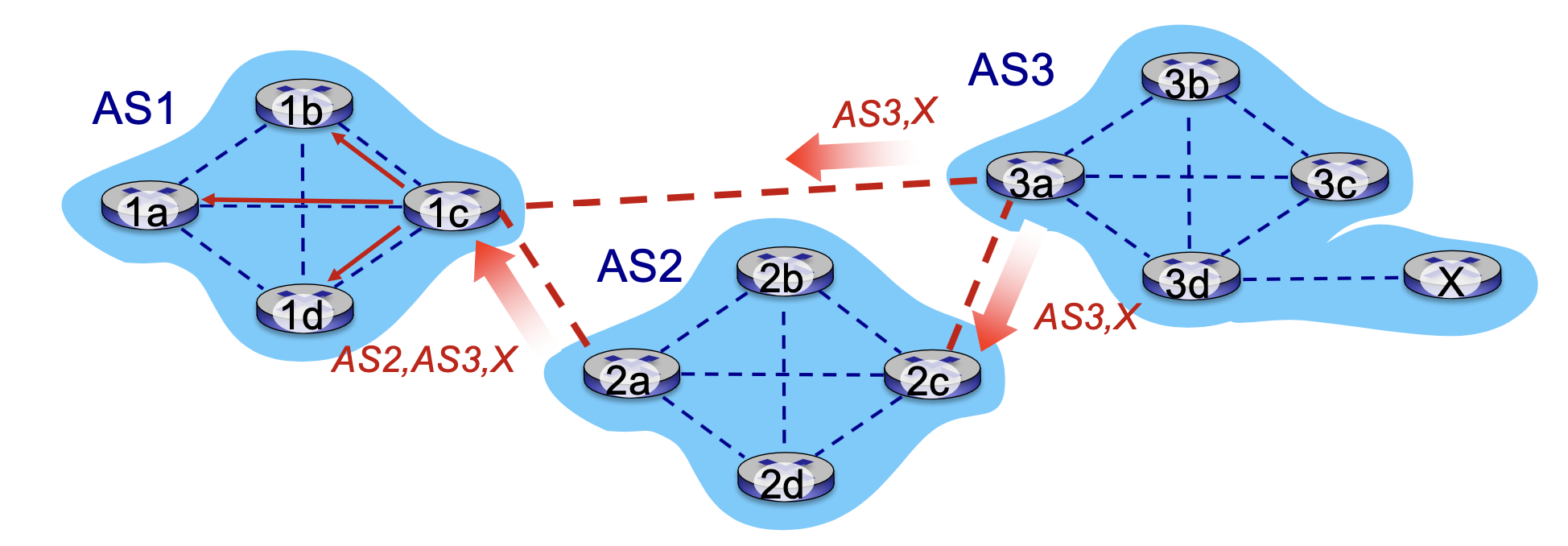
그럼 1c도 이 정보를 또 내부적으로 전파를 하겠죠.
이번에는 조금 더 복잡한 토폴로지 생각해 봅시다 다음 그림에서 이번에는 이렇게가 연결이 추가가 됐어요.
as 1이랑 as3랑 연결이 된 거예요.
그래서 이번에 게이트웨이 라우터는 아마 여러 개의 경로를 동시에 배울 겁니다.
지금 as1 게이트웨이 라우터 1 c 같은 경우는 as2를 통해서 as3를 통해서 x에 갈 수 있다는 정보를 배웠죠. 근데 최근에 1c랑 3a가 다이렉트로 연결되면서 이 정보도 새롭게 받았어요.
as3를 통해서 x에 바로 갈 수 있다라는 정보를 받았기 때문에 1c 입장에서는 이제는 x에 가는 방법이 두 가지죠.
그러면은 여기서 뭘 선택할 거냐도 포인트입니다. 우리가 항상 기억해야 되는 거는 이 인터 as 라우팅은 알고리즘에 의해서 결정되는 게 아니라 policy 의해서 결정된다는점 입니다. 그냥 상식적으로 봤을 때는 2번이 더 좋아 보이죠. (1c->3a)
더 좋아 보이지만 사업자의 정책이 있을 수도 있고 여러 가지 이해관계가 있을 수가 있어서 policy에 의해서 이렇게 오해하는 경우를 택할 수도 있고 아니면은 이쪽 경로를 택할 수도 있습니다.

그래서 폴리스에 의해서 여기 예시에서는 based one policy에 기반해서 as1 라우터가 이 1c경로를 채택했다고 합시다. 1c가 이 as3 x 경로를 채택을 했다고 합니다. 이 두 가지 방법 중에서 지금 이 다이렉트를 선택한 거예요.
그래서 선택한 경로를 ibgp로 내부에다가 전파를 합니다.
이걸 선택을 왜 해야 되냐면은 선택을 안 하고서 안 하면은 내부에서 혼란스럽잖아요. 그래서 하나를 딱 선택해서 그걸 내부에 딱 전파해 줘야지 내부에서는 어디를 통해서 어떻게 갈 수 있구나라는 것을 알 수가 있는 거죠.
그래서 지금 한번 어떻게 외부 쪽으로 어떻게 라우팅이 되는지를 한번 우리 살펴볼게요. 지금 1c가 앞에서 배운 경로 즉 x는 3a를 통해서 갈 수 있다라는 정보를 배웠잖아요. 그거를 내부에다 이제 전파를 하고 있습니다. 그래서 이제 각각의 라우터들도 다 배웠습니다.
배우면은 목적지 x는 일단은 1c 앞에만 가면 된다라는 것만 알게 됩니다. 1c 이후에 어떻게 되는지는 이 내부 라우터는 신경 쓸 필요가 없어요. 왜냐하면 그거는 이제 1c가 알아서 해주면 돼요. 게이트웨이 라우터가 그러니까 얘네들은 x로 가려면은 1c라는 게이트웨이 통해서 가면 된대라는 것까지만 알면 돼요. 그래서 4d 테이블이 다음과 같이 만들어집니다.
뭐냐면은 데스티네이션 x라는 서브넷은 인터페이스 1로 보내면 된다고 왜냐하면 1d 입장에서는 1로 보내는 게 1c한테 가는 길이잖아요.
그래서 라우터 1a 1b 1d는 바로 ibgp라는 프로토콜을 통해서 데스티네이션 x에 대해서 배우게 됩니다.
그리고 지금 1b 입장에서는 ospf intra domain routing은 만약에 1c에 도달하기 위해서 이 인터페이스 1을 통해서 이제 가면 된다라는 것을 포워딩 테이블에 이제 입력을 하게 되고 그걸 통해서 이제 이제 인터페이스 원으로 라우팅 해주는 겁니다.
2-6. BGP : Hot Potato Routing
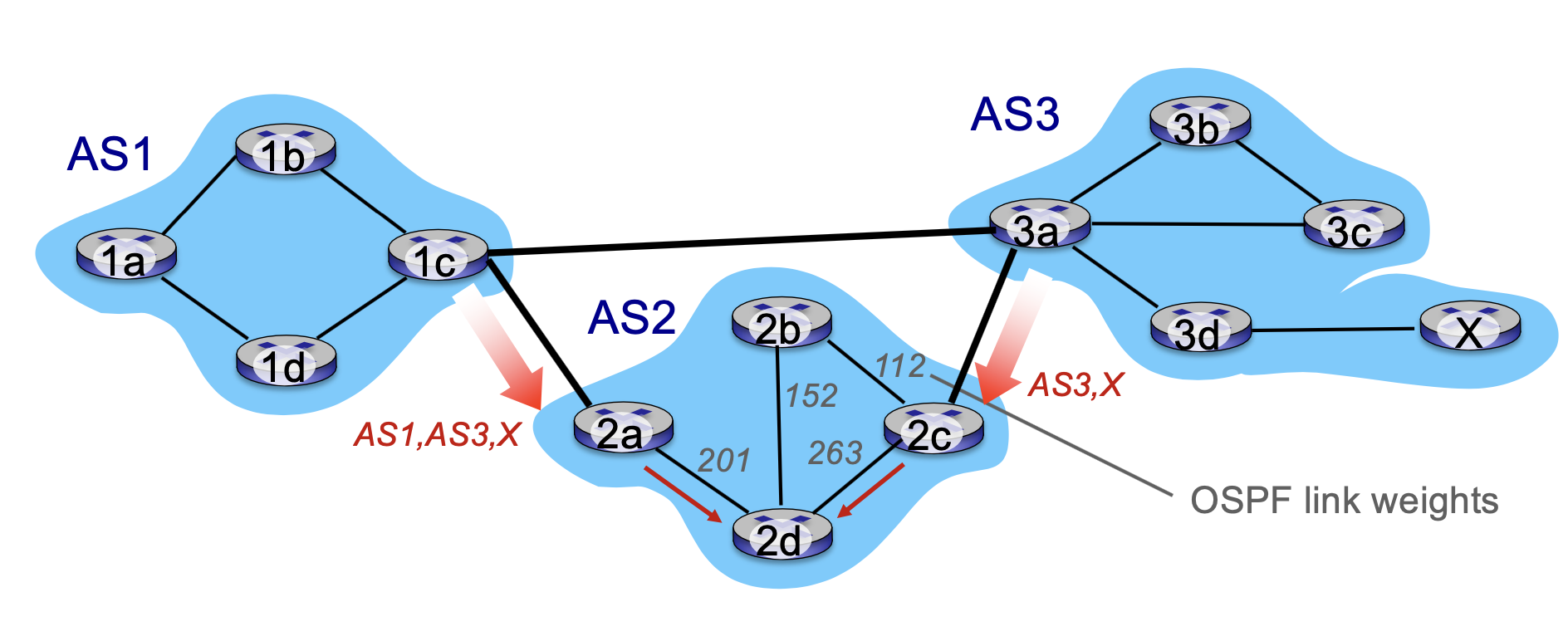
Hot Potato Routing이 뭐냐면은 다음과 같이 x에 가는 경로를 두 개의 게이트웨이가 배운 거예요. 조금 복잡한 경우죠. 지금 as2는 게이트웨이 라우터가 2개가 있잖아요. as3를 통해서 x로 갈 수 있대라는 걸 배워가지고 전파를 했어요. 근데 2a도 배웠어요. 2a도 as1을 통해서 as3를 통해서 x에 갈 수 있다라는 경로를 배웠습니다.
그러면 얘네들은 어차피 각자 배운 거잖아요. 각자 배운 거니까 ibgp를 통해서 전파를 시킬 거예요.
그 전파를 시키면은 이제 만약에 라우터 2d 입장에서는 만약에 x라는 목적지가 x 패킷을 받았어요.
그러면은 누구한테 보내야 될까 이걸 결정해야 되죠 아까는 하나만 결정하고 하나의 목적지가 딱 하 게이트웨이 하나만 딱 찾으면 되니까 쉬운데 문제는 게이트의 두 개가 둘 다 나를 통해서 x에 갈 수 있다를 알려주니까 헷갈리는 상황이 발생하는 겁니다.
2d 입장에서 지금 2c까지는 코스트가 263이고, 2d 입장에서 2a 까지는 코스트가 201이에요.
그럼 어떤 게 더 코스트가 적나요. 2a가 더 적죠 그래서 여기서 Hot Potato Routing은 뭐냐면은요 이 as 라우팅 이외에 바깥 경로는 신경 쓰지 말고 내가 게이트웨이까지 가는 비용만 고려해가지고 결정하는 게 Hot Potato Routing 입니다.
내가 일단 x로 가려면 나는 2a랑 2c 둘 중 하나를 통해서 갈 수 있잖아요.
내 2a랑 2c 중에 어디가 가까우냐 그것만 판단하는 게 인트라 as 라우팅의 역할입니다.
그래서 여기서는 어디를 선택한다 바로 2a를 선택을 하게 됩니다.
그래서 2d는 바로 로칼 게이트웨이 가장 적은 비용을 발생시키는 로칼 게이트웨이를 선택해서 2a를 선택하면은 a를 통해서 1 c를 통해서 이렇게 라우팅이 되는 거예요.
익스터널로 가는 경로가 두 개의 게이트웨이가 있어요.
그럼 두 개 게이트 중에서 어떤 경로가 최적일까 그거는 내가 판단할 수 없는 영역이다라고 보는 거예요.
내가 판단할 수 없는 경우니까 내가 판단할 수 있는 건 뭐냐면은 그럼 두 개의 게이트웨이 중에서 뭐가 더 가까운데 내 입장에서는 그냥 단순한 정보만 가지고 라우팅하자는 겁니다. 그래서 여기서는 두 개의 게이트 중에서 보다가 2c보다 더 비용이 적네 그러니까 2a로 선택하겠다는 거예요.
물론 결과적으로는 2a를 통해서 보내는 게 돌아가죠. 돌아가지만 그것까지 판단해서 라우팅하기에는 라우팅 알고리즘이 너무 복잡해지고 우리가 인프라 as 라우팅이랑 인프라 as 라우팅을 분리했잖아요.
그러니까 인프라 as 라우팅은 인프라 as 관점에서만 최선을 다하게끔 내이 두는 겁니다.
그게 물론 아주 최적은 아니겠지만 그게 Hot Potato Routing입니다.
먼저 policy 관점에서 보면은요 inter-as는 즉 어드미니스트레이터, 관리자가 이제 컨트롤을 합니다. 트래픽이 어떻게 라우트될지 즉 policy 기반으로 컨트롤합니다.
근데 인프라 as 같은 경우는 이제 싱글 어드민이고 폴리시가 적용이 되지 않습니다. 폴리시가 적용이 되지 않는다는 말은 어떤 알고리즘에 의해서 이제 알아서 이제 라우팅 테이블이 만들어지고 그걸로 라우팅이 된다. 이 말이죠.
그리고 scale 같은 경우는 이제 이렇게 우리가 라우팅 도메인을 전 세계를 플랫하게 하나의 도메인으로 놓지 않고 이렇게 as 단위로 쪼개가지고 이렇게 계층적으로 운영하니까 테이블 사이즈가 작아지겠죠.
그리고 이 트래픽 업데이트하는 트래픽도 굉장히 줄어들게 됩니다. 그러니까 훨씬 더 scalable하게 라우팅을 적용할 수 있게 됐다.
퍼포먼스 관점에서 보면은 인트라 as 라우팅은 성능에 초점을 맞춘 라우팅 방식이고요 그리고 인터 as는 성능보다는 어떤 사업자의 정책이 조금 더 우선을 하는 라우팅 프로토콜이다. 이렇게 정리를 할 수 있겠습니다.
3. SDN control plane
이번에는 이제 지난번에 우리 배웠던 이제 sdn의 컨트롤 플레인에 대해서 이야기를 해볼게요. 우리 sdn 배웠죠 sdn은 지금 우리가 사용하고 있는 라우팅을 소프트웨어 기반으로 이제 변화시키는 기술이라고 했고요.
그리고 조금 조금씩 지금 많이 적용이 되고 있는 단계라고 이야기를 했습니다. 그러면은 만약에 sdn이 적용이 되면은 우리가 지금 배웠던 이 라우팅 알고리즘 결국 컨트롤 도메인이죠. 이 컨트롤 도메인이 어떻게 이제 구조가 바뀌게 될까 그 부분에만 조금 초점을 맞춰서 sdn control plane 이야기를 여기서 해보려고 합니다.
일단은 과거의 인터넷 그리고 사실상 지금까지의 인터넷은 디스트리비티드 디스트 비치라는 분은 라우터가 이게 전 세계에 분산돼서 깔려 있잖아요.
분산돼서 깔려 있고 퍼 라우터 어프로치로 적용이 됐습니다.
그리고 각각의 라우터는 어떤 걸 가지고 있냐면은 스위칭 역할을 하는 하드웨어랑 그리고
참석자 1 0:19:15
다양한 이 이 라우팅 프로토콜을 구동하기 위한 소프트웨어를 탑재를 하고 있습니다.
그렇기 때문에 굉장히 고가의 장비였었고요 그리고 라우트뿐만 아니라 다양한 리들 박스들을 네트워크 운용에 필요로 한다고 이야기를 했습니다.
근데 이런 어프로치가 2005년까지는 어떻게 보면 너무나도 당연스럽게 받아들여지다가 2005년도에
참석자 1 0:19:38
이거를 좀 우리가 새롭게 디자인을 할 필요가 있다라는 이제 이야기가 나오고 연구가 시작이 됐습니다.
그러니까 연구는 굉장히 빨리 시작됐죠 하지만 아직까지도 시장에서 아주 빠르게 적용되고 있지 않아요.
그러니까 어떤 질문이냐면은 우리가 한번 센트롤 라이스 된 컨트롤 플레인을 설계해 볼 수 없을까 지금은 어떻게 보면 컨트롤 플레인이 각 라우터마다 들어있는 거죠.
참석자 1 0:20:04
그간 각 라우터가 분산돼서 이 컨트롤 플레인을 동작시키는 구조예요.
그런데 이 컨트롤 플레이는 그냥 어떤 센트라이드 클라우드 서버 같은 게 있다면은 그 클라우드 서버가 이제 컨트롤 트레인 돌리고 어떻게 보면 더미한 이러한 스위치나 라우터들을 제어하는 방식을 우리가 바꿀 수 있지 않을까 그러면은 라우터는 굉장히 단순한 장비가 되고 어떻게 보면 브레인 역할 하는 기능들은 모두 다 어떤 center lig의 서버에 올라가니까
참석자 1 0:20:32
이 관리자 입장에서는 더 쉽거든요. 관리자 입장에서는 라우터가 만약에 100개 있다고 해봅시다 그럼 100개를 다 컨피그레이션 하고 제어하는 게 편할까요.
아니면은 서버 한 대에서 서버 한 대에서 컨트롤하면서 이 그냥 라우터들 작작작작 명령 내리면서 제거하는 게 편할까요.
그렇죠 그 어떤 기능을 추가할 때도 생각해 보면은 100개 라우터의 기능 다 컨트레이션 하면서 제어하는 것보다는 그 소프트웨어의 기능이 한 곳에 딱 모여 있어서 서버에서 제어하는 게 훨씬 빠르겠죠.
참석자 1 0:21:00
그러니까 이런 기능을 어떻게 보면 사업자 입장에서는 당연히 선호하는 기능인데 이런 것들이 지금까지 적용이 안 됐었다는 거죠.
그래서 네트워크 관리 측면에서 훨씬 더 쉬워진다.
그러니까 어떤 라우터를 잘못 컨퓨게이션 한다거나 아니면은 더 유연하게 라우팅을 한다거나 이런 기능들 적용이 어려웠었는데 이런 것들을 이제 개선할 수가 있다라는 거고요 그리고
참석자 1 0:21:28
테이블 베이스 포워딩을 하게 되면은 우리가 라우터들을 이제는 프로그래밍 라우터로 만들 수가 있다.
이게 혹시 무슨 말인지 알까요. 프로그래밍이라고 그렇죠 네 그러니까 그런데 지금도 라우터에는 소프트웨어 기능이 들어가잖아요.
근데 왜 지금은 왜 프로그램인 라우터가 아닐까요.
현재는
참석자 1 0:22:00
그렇죠 그러니까 어떻게 보면 제조사가 모든 기능을 컨트롤하죠.
그러니까 시스코라고 하는 제조사가 그럼 시스코어가 제공하는 기능만 탑재할 수 있죠 다른 서드 파티나 개인이 거기에 아무리 좋은 기능이 있다라고 해도 시스코 라우트에 넣을 수 없죠.
근데 만약에
참석자 1 0:22:20
이 라우터는 진짜 아주 하드웨어적인 기능만 담당하고 모든 소프트웨어 기능이 클라우드 같은 데 그냥 프로그램 식으로 올라오면은 너도나도 참여할 수 있겠죠.
라우 마치 마치 이게 뭐냐면은 우리 스마트폰 이전에는 피처폰이었잖아요.
그때 피처폰일 때는 모든 기능이 딱 빌트에서 나왔거든요.
그럼 그때는 내가 재밌는 게임 같은 거 핸드폰에 넣고 싶어도 넣을 수 있었나요.
못 넣죠. 오직 넣을 수 있는 사람 넣을 수 있는 조직은 뭐죠
참석자 1 0:22:51
제조사 제조사 그러니까 만약에 삼성에서 삼성 휴대폰 만들면은 삼성 휴대폰에 딱 빌트 있는 기능만 들어갔었던 거잖아요.
그게 바뀌었죠. 스마트폰으로 나오면서 스마트폰 나오면서 어떻게 보면 삼성이나 이런 제조사는 이 하드웨어를 제공하는 거고 그 하드웨어 위에 이제 우리가 앱을 깔게 됐잖아요.
그러면은 너도 나도 이제 앱 개발할 수 있잖아요.
지금 여러분도 앱 개발해서 마켓 플레이스에 올리면은 사람들이 선택만 해주면은 쓸 수 있는 거잖아요.
참석자 1 0:23:19
그러다 보니까 스마트폰에서 사용할 수 있는 소프트웨어가 기업 수적으로 늘었죠.
예전에 피처폰에 비교해서 그 라우터도 똑같아요.
만약에 내가 시스코보다 더 좋은 라우팅 알고리즘을 내가 알고 있어 그걸 내가 구현까지 했어 그렇다고 해서 시스코 넣어줄까요.
실리콘은 자기네가 이미 시장도 가지고 있고 어떻게 보면 여러 가지 계산기 두들겨 보고 오히려 더 단순한 기능이 지금 경쟁력이 있으면 더 단순한 기능으로 계속 시장을 유지할 수도 있는 거예요.
참석자 1 0:23:48
굳이 어드밴스 기능을 넣는 게 무조건 좋은 게 아니잖아요.
근데 만약에 이 이 소프트웨어가 오픈이 돼서 너도나도 경쟁이 치열해지면은 너도나도 좋은 경쟁으로 이 시장을 먹으려고 경쟁이 치열해지면 사용자 입장에서 더 이득이죠.
그러니까 더 좋은 라우팅 알고리즘이 개발될 수도 있고 우리가 생각하지 못했던 다양한 네트워킹 애프리케이션들이 나올 수가 있는 거거든요.
참석자 1 0:24:12
그래서 그렇게 이제 바꾸는 게 sdn의 이제 핵심이라고 보면 되겠어요.
네 그러니까 피처폰에서 스마트폰으로 바뀌듯이 기존에 이제 라우터 그래서 이제 sdn으로 변화되는 거죠.
이게 2016년도에 참고로 그냥 보면 되는데요.
2016년도 이때
참석자 1 0:24:40
스위치 라우터 시장이라고 해요. 여기서 딱 봤을 때 뭐가 많이 보여 무슨 색깔이 많이 보여요 다른 색 많이 보이죠.
이게 다 시스코거든요. 시스코가 50% 이상은 항상 시장을 계속 유지하고 있었어요.
지금도 그렇고
참석자 1 0:25:01
이거는 지금 설명 제가 스마트폰에 비유해서 설명했는데 여기 교재에서는 메인 프레임에서 pc로 변화하는 거랑 비슷한 변화다 이렇게 이야기를 하고 있네요.
그러니까 비유로는 비슷한 것 같아요.
또한 메인 프레임이 사실 저는 이 메인 프레임 세대가 아니어가지고 저는 오히려 피처폰에서 스마트폰으로 변화되는 게 저희 세대에서는 더 친숙한 이유인데 옛날 기준으로 했을 때는
참석자 1 0:25:26
이 메인 프레임에서 이제 퍼스널 컴퓨터 시대로 이제 바뀐 거를 비유로 들고 있습니다.
그러니까 예전에 메인 프레임일 때는 하드웨어랑 오스랑 액플리케이션이 세트로 컴퓨터에 딱 박혀 있었다고 합니다.
근데 이게 쪼개지면서 os 시장이 열리고 애플리케이션 시장이 열리고 그리고 하드웨어 시장이 열리면서 이게 각각이 다 디커플 됐어요.
참석자 1 0:25:48
그러니까 이제는 이 하드웨어 만드는 제조사 있고 os 만드는 회사 있고 애플리케이션 만드는 회사 있죠 지금 그게 우리 당연하죠.
옛날에는 이게 다 패키징 돼가지고 메인 프레임으로 나갔다고 합니다.
사실 저도 이 시대에 살지는 않아가지고 익숙하지 않은데 근데 이 메인 프레임에서 pc로 넘어갈 때도 이런 식으로 디커플링이 됐는데 근데 이상한 게 지금 이 네트워크 장비는
참석자 1 0:26:10
아직도 요 컨셉트에 머물러 있다는 거예요.
매터킹 장비는 그러니까 이렇게 넘어갈 수도 있는 거죠.
참석자 1 0:26:20
그렇기 때문에 지금 라우팅 장비가 굉장히 고여 있다.
어떻게 고여 있냐면은 기존의 라우팅 알고리즘이 딱 적용되면은 그 틀을 못 벗어나는 거예요.
그래서 예를 들면은 우리가 이제 라우팅 알고 좀 배웠잖아요.
만약에 네트워크 사업자가 어떤 특별한 목적이 있어가지고 어떤 트래픽의 u에서 위랑 네 u에서 뒤로 가는 트래픽 여기서 여기로 가는 건데
참석자 1 0:26:47
얘를 이렇게 스프리킹을 하고 싶대요 로드 밸런싱 하기 위해서 이러한 라우팅 알고리즘을 적용할 수 있나요.
우리가 배운 걸로 딱 떠오르지가 않죠.
다익스 알고리즘 돌려가지고 이렇게 스프리팅 어떻게 하는 게 안 떠오르죠.
잘 그렇죠 혹은 이런 것들 만약에 이 w가 빨간색 트래픽이랑 파란색 트래픽을 좀 다르게 처리를 하고 싶대요
참석자 1 0:27:15
예를 들면은 어떤 좀 빨간색 트레이프가 조금 더 돈을 더 많이 해서 프리미엄 유죠 그리고 파란색 유저를 좀 좀 돈을 적게 내는 유저 일반 유저라고 하면은 프리미엄 유저는 조금 더 빠른 경로로 보내고 좀 요금을 덜 낸 유저는 조금 더 느린 정도로 보낸다든지 이러한 프라우티 처리를 하고 싶을 수도 있잖아요.
근데 여기 그림에서는
참석자 1 0:27:39
빨간색 트래픽은 1로 가고 하고 파란색 트레이프는 여기 아래로 가게끔 하는 라우팅을 우리 배운 방식으로 할 수 있나요.
디스턴스 벡터 링크 스테이크 알고리즘으로 이러한 처리할 수 있는 그렇죠 안 되죠 그니까 사업자 입장에서는 여러 가지 예외 상황이나 자기네들이 뭔가 새로운 기능들을 라우팅 할 때 적용하고 싶은데 지금은 적용할 수가 없어요.
왜냐하면
참석자 1 0:28:03
통신사들도 그냥 라우터 사서 사업하는 거지 자기들이 라우터를 수정하고 할 권리가 권한도 없고 기술자도 없잖아요.
그냥 라우터 사서 세팅해놓고 거기서 지원되는 기능만 사실상 할 수가 있는 거거든요.
그래서 이 sdn은 뭐냐면은 이 라우터에서 돌아가는 이러한 라우팅 기능들 즉 컨트롤 플레인 기능들을 라우터에서 쭉 위로 올리자는 거예요.
위로
참석자 1 0:28:31
위로 올려서 이제는 이 라우터는 말 그대로 포워딩 기능만 하도록 남겨놓고 모든 소프트웨어적인 기능 컨트롤 플레이 기능들을 이렇게 이 센처라이즈로 묶어서 어느 pc나 서버에서든지 돌아갈 수 있게끔 하자라는 거예요.
그리고 오픈하죠. 그럼 오픈하면은 이제는 너도 나도 달려들어서 좀 다양한 기능들 개발하면은 어때 사업자 입어서 우리 자유롭게 그거 선택해서 쓰는 거야
참석자 1 0:29:08
그래서
참석자 1 0:29:15
데이터 플레인 스위치 부분을 보면은요 페스트 심플 커머비티 스위치 이제 일반적으로 데이터 플레이 포어링 기능을 담당하고요 그리고 이 스위치 후 테이블은 계산된 다음에 이제 컨트롤러에 의해서 이제 인스트롤 됩니다.
그리고 이러한 케이블 베이스 스위치 컨트롤을 위한 ap
참석자 1 0:29:40
아이가 또 필요하게 됐고요 그리고 이 컨트롤러와 서로 소통하기 위한 프로토콜이 필요합니다.
그래서 이 프로토콜은 지금 정의 오픈플로우라는 프로토콜을 사용하고 있어요.
sdr에서는 그래서 오픈플로우라는 프로토콜이 이게 약간 배경이 달라요 그러니까 지금까지 모든 네트웍 관련된 프로토콜은 itf it ie
참석자 1 0:30:05
tf라는 국제표준화에서 tcpip 모든 네트워크와 관련된 기술 프로토콜을 거기서 정리를 했거든요.
근데 이 오픈 플로우는 그런 딱 이 itf에서 표준한 게 아니고요 오픈 소스 커뮤니티 개발자들이 이게 만들면서 기능이 애드온데고 마치 리눅스가 만들어진 거와 비슷하게 오픈 소스 커뮤니티 사람들이 만들고 도큐멘테이션 화를 하다가
참석자 1 0:30:28
점점점점 사람이 많이 붙으니까 이게 대세가 돼가지고 sdn은 오픈플로우 기반의 프로토콜을 사용하고 이걸로 구현하자라고 하면서 어떤 공식 화된 국제 표준 기구가 아닌 이렇게 오픈소스 커뮤니티들이 점점점점 발전해가지고 만들어진 프로토콜이거든요.
그래서 이제 구글이나 이런 데서 이 오픈 플로우를 직접적으로 사용하고 sdn 구현할 때 사용하다 보니까 사실상 거의 공식 프로토콜처럼 됐어요.
근데 약간 배경이 조금 다르죠
참석자 1 0:30:54
지금까지 인터넷 프로토콜을 주도하던 메인 스트림에서 만든 게 아니라 이런 소프트웨어 스트림에서 오픈 소스 스트림에서 주도해가지고 만들어진 프로토콜이 지금 네트워크 영역으로 들어오고 있는 거예요.
네 그래서 sdn 컨트롤러 sd 컨트롤러는 네트워크 os라고 봐도 될 것 같아요.
그래서 이 네트워크 os라는 개념이 사실상 없었는데
참석자 1 0:31:20
이제는 컨트롤 플레이을 떼내다 보니까 이 컨트롤 플레인을 마치 네트워크의 오스처럼 우리가 바를 수가 있게 된 거거든요.
그래서 여기 보면은 이제는 밑에 sdn 컨트롤도 스위치가 있죠.
얘는 컨트롤 플랜이 없는 애들이에요.
컨트롤 플랜이 없고 그냥 포워딩 기능만 있고 이 컨트롤러가 시키는 대로 동작하는 애들입니다.
데이터 플레이 기능만 사용하는 그리고 얘네들을 직접적으로 제어해주는 sdn 컨트롤러가 있는데
참석자 1 0:31:48
얘가 이제 사실상 오퍼레이팅 시스템 역할을 해주는 겁니다.
그래서 네트워크 보이스는 그러면 기존 pc랑은 어떤 차별화된 기능이 있어야 되느냐 일단은 얘네들의 어떤 링크 스테이트 정보들을 수집해서 관리를 해야 됩니다.
그래서 네트워크 스테이트 정보들을 보관하고 있는 역할을 하고요 그리고 이 사우스 바운드 api 즉 이 남쪽 방향 사우스 바운드 api를 통해서
참석자 1 0:32:14
이 스위치들을 제어하는 역할을 해줘야 됩니다.
이 제어라고 하는 건 뭐냐면요. 이 스위치한테 포워딩 케이블을 내려주는 역할을 하는 거예요.
원래 라우터가 자기가 직접 포딩 캡을 계산했잖아요.
근데 이제는 라우터가 소프트웨어 기능이 없다.
보니까 직접 포딩 캡을 계산을 못해요.
그 컨트롤러가 내려줘야 돼요 포워딩 테이블을 그래서 이
참석자 1 0:32:39
sdn 컨트롤드 스위치한테 계산된 포워딩 테이블을 내려서 인스톨 해주는 역할을 해줘야 됩니다.
그러면 얘네들은 전달받은 포딩 태그대로 포워딩만 해주는 역할을 하는 거예요.
참석자 1 0:32:52
그리고 이 컨트롤러가 이렇게 그림상으로는 센트라이 돼 있지만 실제로는 여러 개가 이제 통합 여러 개가 분산돼서 운영되는 게 이제 로지 카라게는 센트럴 라이즈 돼 있지만 실제로는 분산된 구조로 운영될 수 있도록 설계가 돼 있다고 합니다.
참석자 1 0:33:16
마지막으로 네트워크 컨트롤 앱스 이거는 우리 애플리케이션이라고 생각하면 되겠어요.
그래서 이 컨트롤러의 기능을 지원받아서 여러 가지 기능들을 구현하는 애플리케이션이라고 보면 되겠습니다.
마치 우리가 os 위에서 애플리케이션이 돌아가잖아요.
이 네트워크 os 위해서 돌아가는 애플리케이션 어떤 애플리케이션이 있을까 대표적으로는 라우팅 애플리케이션이 있을 수 있겠죠.
참석자 1 0:33:43
그래서 이 브레이스 오브 컨트롤 그러니까 인플리먼트 컨트롤 펑션스 유징 롤 레벨 서비시스 api 프로바이드 바이 sdn 컨트롤러 이렇게 돼 있어요.
그래서 sdn 컨트롤러가 제공하는 서비스를 지원받아서 구현할 수 있는 다양한 네트워크 애플리케이션 기능들을 말을 합니다.
그래서 쉽게 생각하면 라우팅인데요. 라우팅에서는
참석자 1 0:34:06
다익스트라 알고리즘을 통해서 엔드 투 엔드 패스를 결정할 수 있겠죠.
이런 기능들 즉 다익스트라 알고리즘의 알고리즘이 여기서 구현이 되는 거예요.
이 애플리케이션 레이어에서 근데 아익스탈 알고리즘을 구현하려면 무슨 정보가 필요하죠 그쵸 링크 스테이 정보 필요하죠 근데 그 정보는 어디서 얻어올까요.
바로 그 정보는 이 sdm 컨트롤러한테 얻어오는 거예요.
참석자 1 0:34:34
이 sdm 컨트롤러가 얘네들로부터 이 링크 스테이트 정보를 받죠.
받아서 애가 보관하고 있거든요. 그럼 얘가 보관하고 있으면은 얘한테서 그 정보를 받아와서 얘가 다 xtr 돌려서 4d 테이블을 계산하면 되는 거예요.
그런 식으로 역할이 분담이 되는 거야
참석자 1 0:34:54
혹은 엑세스 컨트롤 기능 이거는 어떤 패켓이 블락될 건지를 결정하는 이런 기능들도 이 애플리케이션 레이어에서 구현될 수 있고요 로드 밸런싱 기능 이거는 스위치 간의 트래픽을 밸런싱 시키는 기능 그러니까 모든 네트워크 장비의 기능들이 이제는 소프트웨어 기반으로 하나의 애플리케이션으로 구현이 될 수가 있다.
그러니까 이제는 이런 것들이 다 네트워크 장비 회사들이 빌트인으로 넣었던 기능들이잖아요.
참석자 1 0:35:21
근데 이제는 네트워크랑 아무 상관이 없는 소프트웨어 회사가 회사 차리고서 이거 개발해서 sdn에서 sdn sdn 컨트롤러랑 인터페이스만 맞춰주면은 우리가 만든 애플리케이션이 시스코보다 성능 더 좋습니다.
앞으로 시장이 커지면 이렇게 홍보할 수도 있다는 거예요.
'CS > 컴퓨터 네트워크' 카테고리의 다른 글
| 컴퓨터 네트워크컴퓨터 네트워크 23일차 : (0) | 2021.11.30 |
|---|---|
| 컴퓨터 네트워크 20일차 : 라우팅 알고리즘, 다익스트라 알고리즘, link state, distance vector (0) | 2021.11.16 |
| 컴퓨터 네트워크 19일차 : 라우터 기능, 방화벽 (0) | 2021.11.09 |
| 컴퓨터 네트워크 18일차 : IP addressing, DHCP, NAT (0) | 2021.11.06 |
| 컴퓨터 네트워크 17일차 : Network layer (0) | 2021.11.03 |